





11/13
共有可能なメタデータの語彙とモデル
神崎 正英
作品のメタデータ
データを公開するときに、どのような語彙とモデルを用いて記述すると共有しやすいのか、判断に迷うことはないでしょうか。図書館、博物館、公文書館などそれぞれの領域で比較的よく用いられる語彙はありますが、個別の館ごとに語彙の組合せやモデルは異なっており、どれを参考にすべきなのか決めがたいものです。複雑な語彙やモデルは手元のデータにはオーバースペックかも知れませんし、逆にシンプルな汎用語彙ではデータの意味がほとんど表現できず領域の専門的な語彙が必要になるかもしれません。
そこで今回は、語彙選択やモデル構築の手順を考えてみることにします。題材は手元の写真です。写真は、美術館の収集対象となるような著名作家のオリジナルプリントから素人撮影のスナップまでさまざまなレベルがあり、応用できる範囲が広そうだからです。

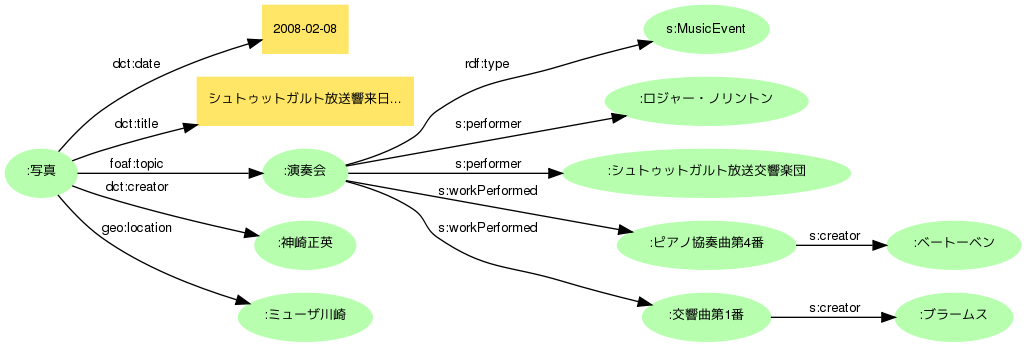
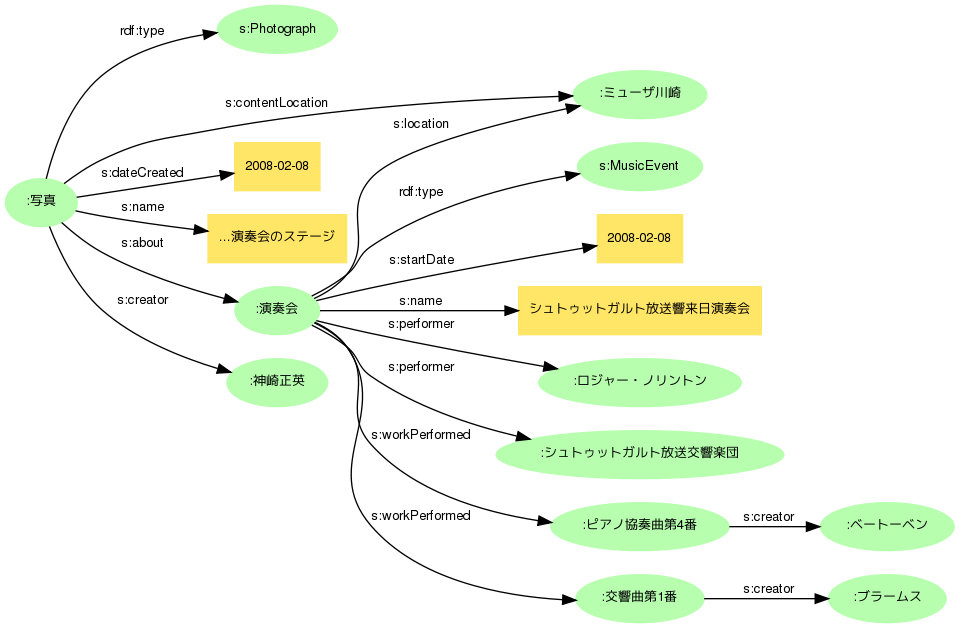
この写真は2008年2月8日にミューザ川崎で行なわれたシュトゥットガルト放送交響楽団の来日公演のステージを筆者が撮影したものです。という自然文での説明を、単純なグラフで表現すると次のようになるでしょう。
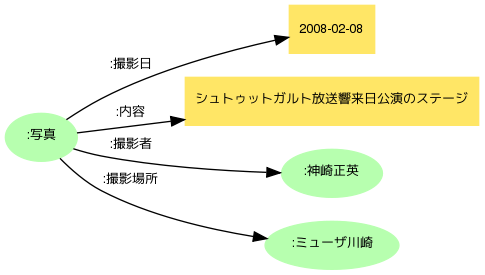
これが共有可能なメタデータになるように、語彙やモデルを検討して記述を改良して行きます。
汎用語彙の組合せ
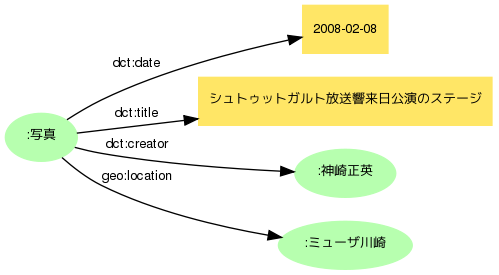
まず語彙の候補としては、カタログ的情報記述の事実上の標準とも言えるDublin Coreが頭に浮かびます(以下接頭辞はdct:)。撮影日はとりあえずdct:dateでいいでしょう。内容説明はdct:descriptionですが、タイトルのない作品メタデータは扱いにくいので、dct:titleとしておきます。撮影者はdct:creatorですね。撮影場所は......。
さてここで行き詰まってしまいました。Dublin Coreには作品の制作地を表すプロパティがないのです。作品の内容(主題)としての場所ならdct:coverageで表現できるのですが、撮影場所にはふさわしくないような気がします。
場所の表現には、緯度・経度の記述によく用いられるW3C基本Geo語彙のgeo:locationを使うことにしましょう。主語と「地点、もしくは空間において幾何的形態を持つもの」との関係を記述するとされているので、コンサートホールが目的語でも大丈夫そうです(語彙の選択は、このようにプロパティの主語/目的語が定義と矛盾しないかの確認が基本になります。あまり気にしなくてよい場合もありますが、目的語は「文書」と定義されているプロパティの値に「人物」を置くと、データを組み合わせた時などにややこしい問題が生じてしまいます)。
イベントのメタデータ
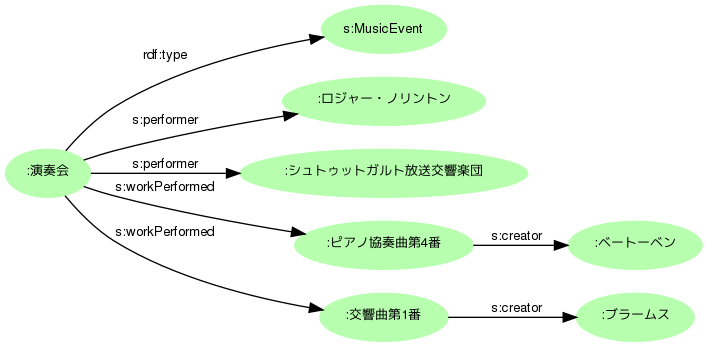
この演奏会では、ロジャー・ノリントンの指揮により、ベートーベンのピアノ協奏曲第4番とブラームスの交響曲第1番が演奏されました。こうした説明は写真のdct:descriptionにテキストで記述してもよいのですが、できればロジャー・ノリントンやベートーベンといった固有名は詳しい情報にリンクさせたいところです。
そのためには、演奏会を独立した情報として扱い、指揮者や演奏曲目を表現する必要がありそうですね。演奏会を精密に記述する語彙は探せばないわけでもないのですが、やや特殊で応用範囲が狭いので、それよりも撮影対象になり得るイベント一般を記述する語彙を考えましょう。
イベントカレンダーという観点ならばicalカレンダーデータとの双方向変換を目指したRDF calendar、またイベントという実体をモデリングするなら英国図書館やBBCも採用しているEvent Ontologyなどがあります。ただ前者はカレンダー項目にない情報(演奏者や作曲家)を記述しにくく、逆に後者は時間も実体として構造記述するなど複雑すぎるため、帯に短し襷に長しです。
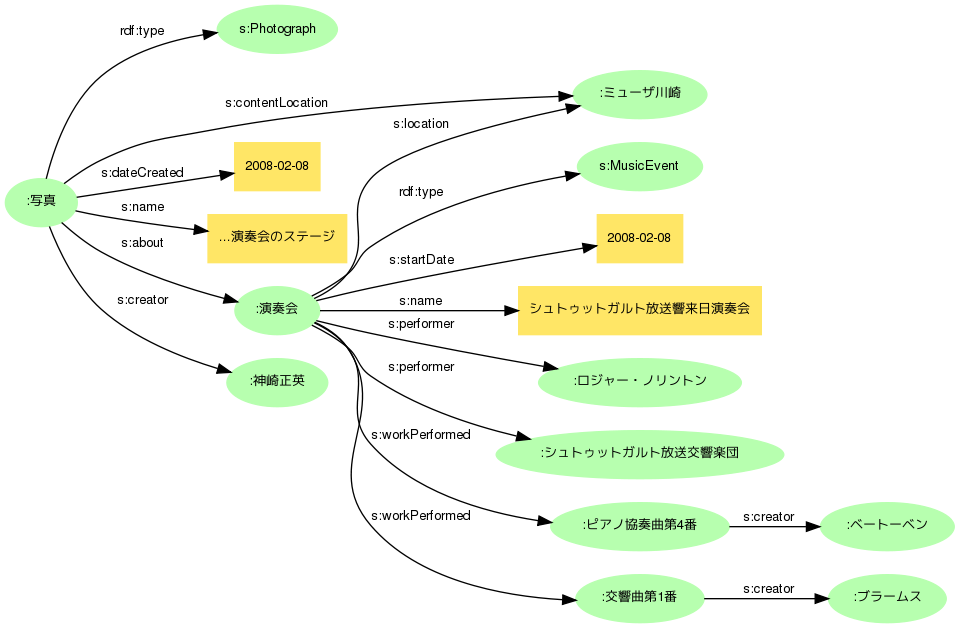
最近注目のSchema.orgには、MusicEventというクラスと関連プロパティが用意されています(以下接頭辞はs:)。これならば、指揮者(およびオーケストラ)はs:performerとして、演奏曲目はs:workPerformedとして記述できます。ベートーベンやブラームスは、それぞれの曲目の作者(s:creator)でよいでしょう。
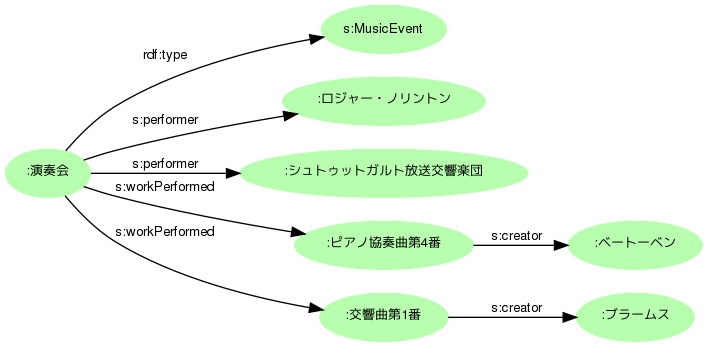
もちろんSchema.orgを用いてイベントの名称や日時、会場なども記述できます。これらは作品(写真)のメタデータと重複することがあるので、次のステップで検討します。
作品とそのトピックによる記述
それでは、演奏会(イベント)メタデータを写真(作品)の「対象」として組合せてみましょう。Dublin Coreであればdct:subjectが"トピック"を表すプロパティですが、この目的語には統制語彙(Web NDL Authoritiesのようなシソーラス)によるキーワードや分類記号が推奨されていてイベント実体では違和感があるので、代わりにFOAFのfoaf:topicを用いて関連付けます。
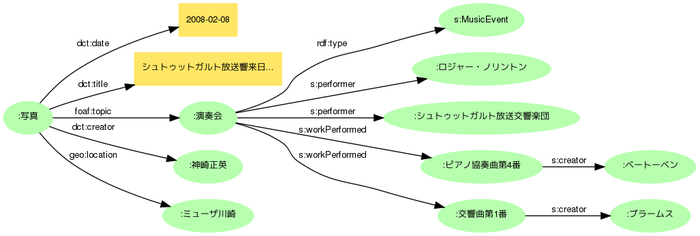
ところで、改めての写真のlocationとは何かを考えると、撮影場所なのか被写体の場所なのか(たとえば新幹線の車窓から富士山を撮った場合、locationはどちらなのでしょう)、あるいはその写真(ファイル)が保管/展示されている場所なのか、意味に曖昧さが残ります。またこのように作品とイベントの記述を併合してみると、ミューザ川崎は撮影地であると同時に演奏会場でもあることに気付きます。曖昧さの問題を避けるためには、ミューザ川崎は演奏会場として記述するほうが具合が良さそうです。Schema.orgならばs:locationでイベントなどの場所を表現できます。
日付はどうでしょうか。イベント写真の場合、撮影日とイベント開催日は同一ですが、たとえば演奏会評のような記事は後日掲載されるのが普通なので、作品とイベントはそれぞれ日付を持つほうが良いことが分かります。Schema.orgでのイベント開催日時はs:startDateです(イベントは複数日に渡るなど期間があるので、開始日時と終了日時を記述できます)。
タイトルも、イベントは「~演奏会」、写真は「~演奏会のステージ」などと使い分けることが可能です。さらに作品とイベントが独立した情報として扱われた場合、タイトル(ラベル)のない情報は前述のとおり利用しにくいものとなってしまうので、いっけん冗長に思われてもそれぞれにタイトルを与えます。
語彙の一本化
イベントをschema.org語彙一本で記述したので、作品(写真)も語彙を揃えてみましょう。複数の語彙を組み合わせてもRDFとしては何の問題もありませんが、実際の記述やデータ利用にあたっては一つの語彙のほうが扱いやすい場合も少なくありません(この点は最後にもう一度考えます)。
Schema.orgでの作品はs:CreativeWorkで、写真はその詳細化であるs:Photographとして記述できます。作者はs:creator、タイトルはより汎用的にs:name、撮影日はs:dateCreated、そして作品のトピックにはs:aboutが使えます。
さらに、s:CreativeWork(およびs:Photograph)にはs:contentLocationというプロパティが用意されており、撮影地と混同することなく被写体の場所を表現できるので、ミューザ川崎はこの目的語とすることもできます。イベントを介して場所は分かるので不可欠ではありませんが、たとえば写真を地図上に表示するアプリケーション等にとっては、このプロパティがあると便利でしょう。
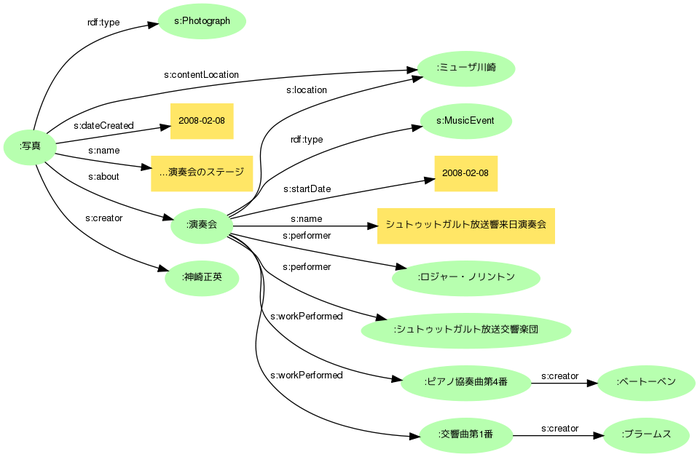
ノード名の共有と非情報リソース
ここまでは語彙の共有に話を絞ってきましたが、グラフのノード名(URI)もきちんと与えなければなりません。データがつながるには、この名前がリンクするデータ(Linked Data)の原則に従っている必要があります。
作品の名前は、ウェブ上で公開している写真ならそのURIでよいでしょう(このようなウェブでアクセス可能なリソースを情報リソースと呼びます)。問題は書籍や収蔵品、あるいは作者やイベントなどネット上にないもの(非情報リソース)の場合です。これらを紹介する情報(たとえばベートーベンに関するWikipediaページ)のURIが使えれば便利ですが、それではウェブページ(情報リソース)と実在した人物であるベートーベン(非情報リソース)の区別ができなくなってしまうのです。
この点についてはさまざまな議論がなされきており、Cool URIs for the Semantic Webなどで具体的な解決策が示されています。その一つは、DBpediaのように非情報リソースのURIとして用意された名前を利用する方法です(このURIにアクセスすると内容を説明する情報リソースのURIに転送されるので「ベートーベンがウェブ上にある」といったややこしい事態に陥りません)。
DBpediaのURIは、WikipediaのURIの項目名部分をそのまま用いるので簡単です。
|
リソース種別 |
サービス |
URI |
|
情報リソース |
Wikipedia |
http://en.wikipedia.org/wiki/Ludwig_van_Beethoven |
|
非情報リソース |
DBpedia |
http://dbpedia.org/resource/Ludwig_van_Beethoven |
日本語の名前なら、Wikipedia日本語版に対応するDBpedia JapanのURIを使うことができます(DBpediaのURIのホスト部がja.dbpedia.orgとなります)。
もう一つの解決策は、ホームページなどのURIにフラグメント識別子を加えて、情報リソースとは別のURIを作る方法です。たとえばウェブの創始者であるティム・バーナーズ=リーは、W3Cサイトに置いた情報のURIに#iを付加することで自分自身のURIとしています。
|
リソース種別 |
意味 |
URI |
|
情報リソース |
バーナーズ=リーについての情報 |
http://www.w3.org/People/Berners-Lee/card |
|
非情報リソース |
バーナーズ=リー自身 |
http://www.w3.org/People/Berners-Lee/card#i |
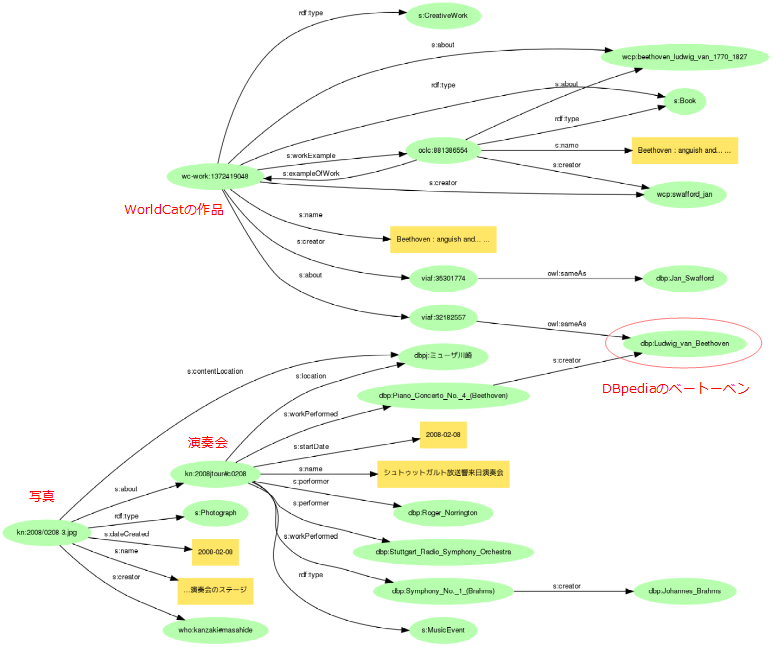
URIで名前付けしたグラフ全体はサイズが大きくなりすぎるので、一部を取り出して図示してみましょう。上段が情報リソースURI、2段目が情報リソース+フラグメント識別子のURI、下の2段が非情報リソース(DBpedia)URIの例になっています。
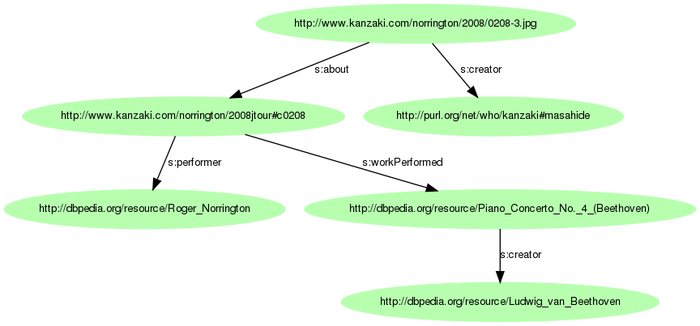
Schema.orgそしてリンクするデータ
Schema.orgは、最上位のThingのもとにAction, BroadcastService, CreativeWork, Event, Intangible, MedicalEntity, Organization, Person, Place, Productという10の上位クラスがあり、さらにその下位クラスを合わせて700を超えるタイプのものごとを表現できる大規模な語彙となっています。Schema.org語彙を用いて記述した作品メタデータは、この非常に広い範囲のデータと連動しやすいという利点が得られるわけです。またDBpediaは2014年9月時点で458万のものごとについて共有可能な名前(URI)を提供しています。
図書館ならばFRBRやRDAに基づく語彙(たとえばRDA Registry)、博物館ならCIDOC CRMに基づく語彙(たとえばErlangen CRM / OWL)など、専門的な目録記述の観点を踏まえた記述語彙もあります。名前のURIも、各国図書館の名称典拠(たとえば前述のWeb NDL Authorities)などそれぞれが培ってきた体系に基づくURIが用意されています。Schema.orgやDBpediaは、精緻さや正確さにおいてはもちろんこれらには及びませんし、目録の情報を全て記述できるとは限りません。それでも、W3CのSchema Bib Extend Community GroupでSchema.orgの拡張が討議され、WorldCatの書誌データやVIAFの典拠データの記述にSchema.orgが採用されたのは、領域を超えたデータの共有・再利用が強く意識されたからでしょう。
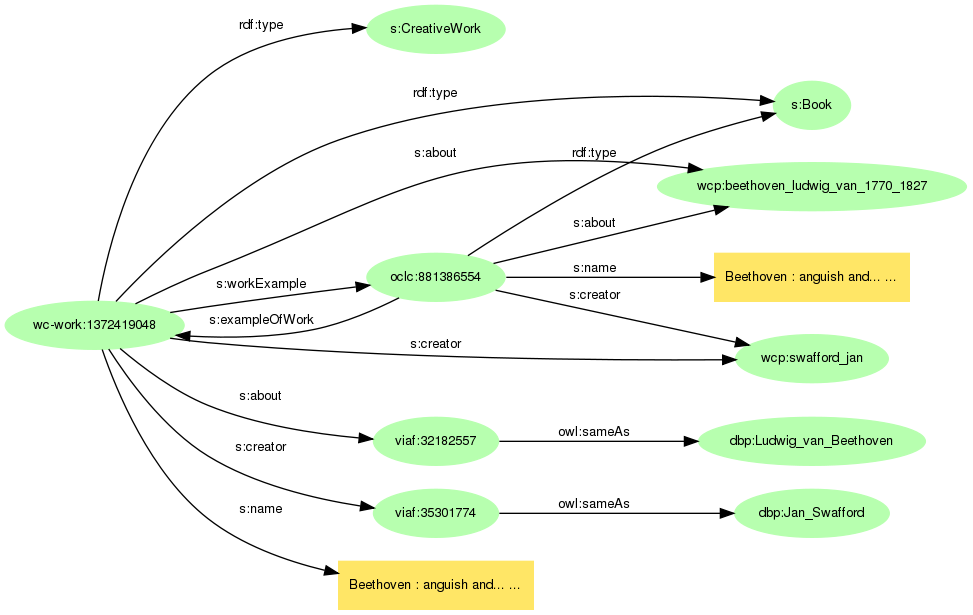
この夏に出版されて評判の高いベートーベンの伝記Beethoven : anguish and triumph : a biographyのWorldCatデータとそこからリンクするVIAFのデータの一部をグラフにしてみましょう。
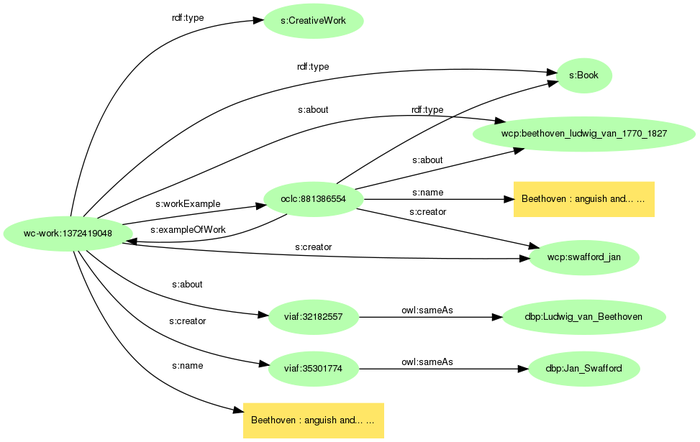
WorldCatのモデルは作品(s:CreativeWork)と書籍(s:Book)の2つのレベルになっています。作者と内容は、書籍からはWorldCat内での実体表現(接頭辞wcp:)につながっていますが、作品からはそれにくわえてVIAFにリンクされ、VIAFはさらにDBpediaにリンクしています。このDBpediaのベートーベンを介して、写真と書籍のグラフがつながることになるのです。
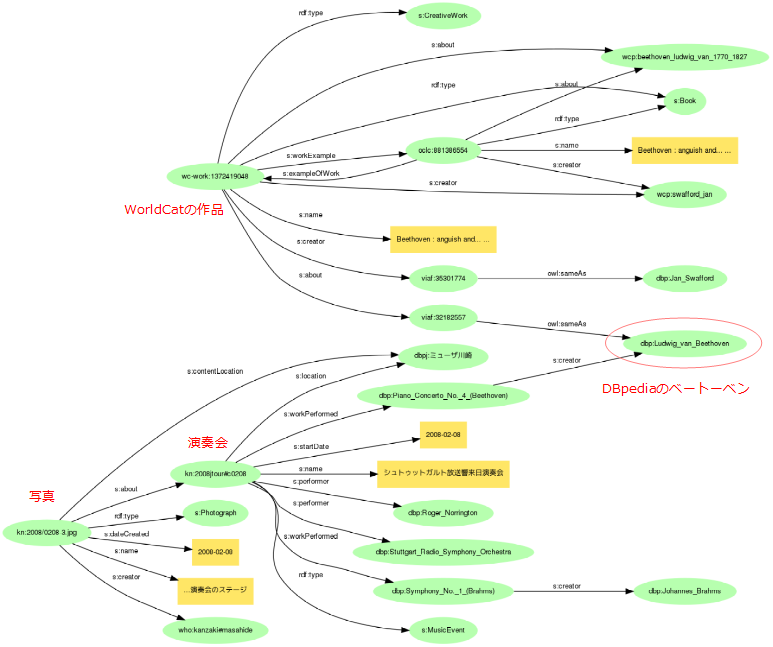
基本プロパティとデータのアクセシビリティ
前節で述べたように、Schema.orgは最上位のThingのもとにさまざまな物事を記述するためのクラス(タイプ)が階層的に定義されています。それぞれのクラスで用いるプロパティは上位クラスの定義を継承して拡張する形なので、Thingのプロパティはあらゆるものごとに共通することになります。データを利用する立場から見れば、情報の種類にかかわらず同じ基本プロパティを用いた検索や処理が可能ということです。
たとえばSPARQLなどで複合データのタイトルあるいはラベルを検索する場合、rdfs:label, dc:title, dct:title, foaf:name, skos:prefLabel...と多くのプロパティをOR検索しなければならず難儀したという経験を持つ方も少なくないでしょう。Schema.orgの場合これらはすべてs:nameですから、話はとてもシンプルになります。
Schema.orgのThingのプロパティは次のとおりです。
|
プロパティ |
意味 |
汎用語彙のプロパティ |
|
name |
対象の名前あるいはラベル |
dc:title, rdfs:label... |
|
description |
対象の簡潔な説明 |
dc:description |
|
url |
対象のURL。たとえばホームページだとか紹介ページのURL |
foaf:page, foaf:homepage |
|
image |
対象を表す/が写っている画像 |
foaf:img, foaf:depiction |
|
alternateName |
別名。ミドルネームなどにも使える |
dct:alternate, skos:altLabel, foaf:nick |
|
sameAs |
対象と同一のもの、あるいはその説明ページ。owl:sameAsより緩やかで、Wikipediaページなども可 |
skos:exactMatch |
|
potentialAction |
対象が目的語となる場合に想定されるアクション。たとえばBookならばReadActionを記述する |
- |
|
additionalType |
対象が1つのクラスにしか属することができないデータ構造や構文の場合に、他のクラスを追記する |
rdf:type |
なかなかSchema.org全面採用にまでは踏み切れない場合でも、上記Thingや今回取り上げたような基本プロパティにはSchema.orgを利用するという方法もあります。どのみち、Schema.orgだけで専門的な内容まで記述できるわけではなく(写真のシャッタースピードや露出を記述したければたとえばEXIF RDF Schemaなどを用いることになります)、語彙の組合せは必要ならためらうことはありません。共通項に同じ土俵でアクセスし、扱えることが重要なのです(※)。
異なるプロパティを使っていても、スキーマでサブプロパティ関係を定義しておけば、アプリケーションがそれを利用して推論できるので、データ共有に語彙の統一は不可欠ではない――それはそのとおりで、それこそがRDFの利点でもあるのですが、多様なデータを扱うときにそれぞれの語彙についてすべて推論を行なうのでは、アプリケーションの負荷は非常に高くなってしまいます。ウェブページにおいては、豊かな表現のためにマルチメディアを組み込んでもテキストによる代替情報を合わせて提供することが、どんな利用者でも使えるアクセシビリティの基本です。同様に、豊かな(領域特有の精密な)情報に加えて代替情報(基本プロパティ記述)も提供することが、データのアクセシビリティと言って良いかもしれません。
目録などの従来のメタデータは、基本的には自分たちが扱う資料を記述し、発見、識別、アクセスするためのものでした。それに対しリンクするデータにおいては、さまざまな分野のデータが混在し、それを領域知識なしにウェブアプリケーションなどが利用するということが前提です。利用する立場でのアクセシビリティを考えることが、共有可能なデータのための重要な一歩なのではないかなと思っています。
※現状では、Schema.orgのみで基本プロパティを記述するよりも、たとえばラベルにはrdfs:labeを用いるほうが広く理解されるかもしれません。一方でウェブアプリケーションを考えるならば、今後Schema.orgの重要性が高まっていくことが想定されます。過渡期でもあるのですが、この点については構文の問題も含め、次回もう少し掘り下げてみたいと思います。
Linked Open Data・RDFの活用ソリューションならインフォコム



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}