





04/03
不思議の国のデータ
神崎 正英
誰もが何についても何でも言える
今年はルイス・キャロルの『不思議の国のアリス』(Alice's Adventures in Wonderland)が1865年に刊行されて150周年にあたります。英ガーディアン紙でその関連記事を読んでいて、ワンダーランドは"referred to a place where anything could happen"という一文に行き当たり、バーナーズ=リーがウェブを"Anyone can say anything about anything"と表現したことを思い出しました(頭文字を取ってAAAと呼ばれます)。
誰もが何について何を言ってもよい。誰にもコントロールされないこの自律分散型の情報環境が、ウェブの大きな力であり、発展の原動力です。一方でこれは、「何について」言っているのかが共有されなければ、情報がきちんと伝わらない世界であることも意味します。だからものごとをグローバルな名前で識別すること、つまりURIを使うことが重要になるのですね。
URIを考える
これまでの記事で、情報をRDFとして記述し、共有可能とする方法を検討してきました。そして、それがウェブ(つまりAAAの世界)で実現されるためにはURIが大切であることを確認してきました。それは分かったとして、実際にデータを記述するとき、何にどんなURIを与えればよいのか迷ったり確信を持てなかったりすることもあるかも知れません。今回はURIについて、いくつかのポイントを具体的に考えてみます。
何にURIを与えるのか
比較的小規模なデータは、表形式のアプリケーションで管理していることが多いでしょう。たとえば第1回の記事では次のような交通計測記録の例を取り上げました。
| ID | 日時 | 計測時間 | 計測地 | 平均値 |
|---|---|---|---|---|
| A00101 | 2014年9月1日午後1時 | 1時間半 | 芝新堀町 | 25.4km/h |
| A00102 | 2015年9月3日午後4時 | 1時間 | 麻布十番 | 18.7km/h |
| ... | ... | ... | ... | ... |
URIが重要だとはいえ、このデータをRDFで表現するとき、何でもかんでもURIを与えるのが良いとは限りません。URIは何か(Anything)を識別するための名前ですから、速度の平均値である25.4km/hのようにそれ自体がデータ値であるものは、そのままの値(リテラル)とする方が扱いやすくなります(ただし第1回で検討したように、値と単位を構造化する可能性はありますが)。
この表の中で「識別されるべきAnything」に相当するものとしては、計測地が挙げられます。「芝新堀町」「麻布十番」はある場所を表す名前ですから、この名前をグローバル化する、すなわちURIとすることがウェブでの情報共有の第一歩です。そうすれば、同じ「麻布十番」で計測した別のデータもURIを介してグラフがつながりますし、外部のデータで「麻布十番」に関連するものも結びつけることが可能となります。
このような「識別されるべきAnything」はしばしば実体(エンティティ)と呼ばれます。RDFのモデル設計では、データがどんな実体で構成されるのかを明確にし、その関連を記述することが重要です。
URIの再利用と自前のURI
ではこれらの実体にはどんなURIを与えるとよいのでしょうか。情報を共有するという観点で考えれば、同じものは同じURIで識別されることが望ましいですから、たとえばDBpediaなどのよく知られたURIを用いるというのは一案です。
DBpediaを調べてみると、「麻布十番」には対応するURIがありますが「芝新堀町」は今のところ登録されていないため、DBpediaだけでは一貫性のある記述ができません。しかも計測地点は「麻布十番」全体というよりもある特定の交差点などを指すわけですから、DBpediaよりも限定的な扱いが望ましいとも言えます。
このような場合は、自データセットの値には自前のURIを与え、対応するDBpediaリソースがある場合にそこからさらにリンクを設けるという設計にすると、具合がよいでしょう。たとえば計測地点は<http://example.org/tokyo/place/麻布十番>というURIで名前付けし、そこからrdfs:seeAlsoなどで<http://ja.dbpedia.org/resource/麻布十番>につなぐのです。そうすれば計測地点「麻布十番」の厳密な住所や緯度経度を、このURIを主語にして記述するなど、データセット独自の情報をうまく管理できます(ここでDBpediaのURIを主語にして関連情報を記述すると、DBpediaの「麻布十番」に情報を追加することになってしまい、不都合が生じかねません)。

自治体コードや業種コードなど、自組織で管理していないコードをURIとして用いたいときに、その発行/管理主体がコードをURI化していない場合も同様です。ウェブは「誰もが何についても何でも言える」のですから、そのコードを誰がURI化しても差し支えありません。
例1
#日本標準産業分類のビール類製造業
http://example.org/code/industry#1022
もちろん、管理主体によるURIの方が信頼感は高くなるでしょうから、そうしたURIがあるならばそれを用いたいところですが、いつ提供されるかわからないものを待っていてはデータをRDFにできなくなってしまいます。将来そのコードのURIが管理主体から提供されたら、上記のようにrdfs:seeAlsoで(あるいは完全に同一のものならowl:sameAsで)関連付ければよいのです。
ただ、管理主体ではなくても公共性の高い組織がコードをURI化していれば、それを利用するのも一案です。たとえばISO639の言語コードのURIは、ISOでは定義されていませんが、米議会図書館が次のような形でURI化しています。
例2
http://id.loc.gov/vocabulary/iso639-1/ja
主語URIを忘れない
こうした表をRDFにするとき、すべての項目をプロパティ=値ペアとして扱って、主語URIのないグラフを作ってしまうことがあります。
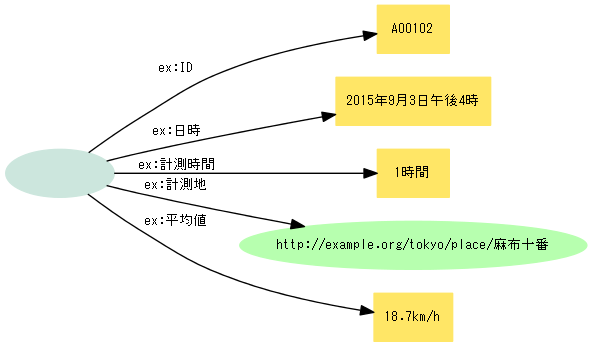
あり得ないと思うかもしれませんが、案外こういうデータが多いのです。主語が空白ノードでは名指して参照することができず、この実体(エンティティ)はsomethingでしかありませんね。実体は原則としてURIを与えて参照できるようにすべきです。
データベースなら通常は主キーとなるフィールドがあり、その値を用いてレコード(行)を一意に識別するようにします。この表ならばIDフィールドがそれにあたるでしょう。表形式のデータをRDFに変換する場合は、この主キーを用いて主語URIを組み立てます。主キーがないなら、とりあえず行番号でもよいでしょう(ただし行を挿入したり並べ替えたりするとURIが変わってしまうので、できるだけIDとなる主キーフィールドを用意しておくべきです)。
IDフィールドの値を、データを公開するファイルURIに連結して実体(レコード)のURIを組み立てます。

表データをRDFに変換するツールの多くは、このように主語のURIとなるフィールドを指定する方法が用意されています。たとえば代表的なツールのひとつであるOpen Refineなら、RDF拡張のEdit RDF Skeleton...メニューを開き、row index (URI)で主語URIのフィールドを選択することができます。
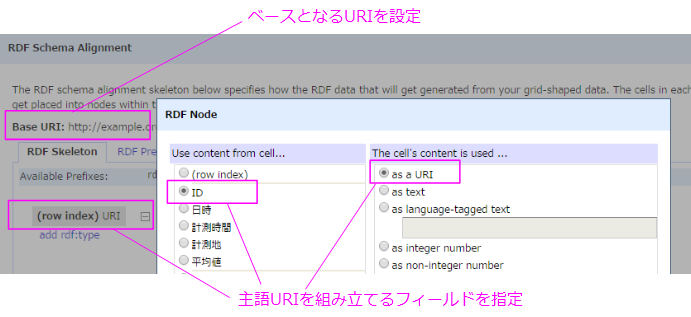
IDフィールドの値そのものをデータとして利用する必要がある場合は、フィールド値を主語URIにするだけでなく、ex:IDプロパティのトリプルも合わせて記述しておけばよいでしょう。
ハッシュとスラッシュ
第1回の記事で紹介した例では、計測データのURIは次のような形でした。
例3
http://example.org/tokyo/survey/traffic/A00102
一方、前項では「IDフィールドの値を、データを公開するファイルURIに連結」として次のようなURIを考えました。
例4
http://example.org/tokyo/survey/traffic#A00102
違いは、A00102というIDフィールド値の前に/を置く(スラッシュ型URI)のか#を置く(ハッシュ型URI)のかという点です。さまざまなRDFグラフのURIを見ると、データ(フィールド)値とベースURIをつなぐ方法としてどちらも広く使われており、いったいどちらにすればよいのか迷うことがあるかもしれません。
区切りに/を用いるスラッシュ型URIは、フィールド値まで含めた全体がURI本体(サーバーにリクエストを送るURI)となるので、このURIにアクセスする場合は識別されているリソース単体の情報を得ることができます。ハッシュ型URIの場合は、#以降はフラグメント識別子となり、アクセスすると#の前のURI本体を共有する情報(ファイル)全体を取得することになります。
規模の大きなRDFグラフ(たとえば図書館の書誌データや典拠データ)の場合、これらが一度に全部返ってくると大変ですから、通常はスラッシュ型URIを用いてレコードに個別アクセスできるようにします。一方、語彙定義のように比較的規模が小さく、関連するクラスやプロパティの定義を一括して取得できる方が都合が良い場合は、しばしばハッシュ型URIが用いられます。
またスラッシュ型URIの場合は、そのURIが直接データを返すと情報リソースを意味することになり、場所や人物などネットワーク上には存在しない実体のURIとして用いる場合には注意が必要です(たとえばDBpediaの場合は、<http://ja.dbpedia.org/resource/麻布十番>にRDFアプリケーションでアクセスすると<http://ja.dbpedia.org/data/麻布十番>に転送されて、そこからRDFグラフのデータが返されるようになっています)。ハッシュ型URIの場合は、情報リソースとなるのは#の前のURI本体なので、この点を心配する必要はありません。
データを1つのファイルにまとめて公開する場合は、ハッシュ型URIを用いるのが自然でしょう。各データの主語URIを相対URIにすれば記述もすっきりします(ファイルがコピーされた時にURIが変わってしまわないよう、基底URIを明示しておきます)。
例5
@base <http://example.org/tokyo/survey/traffic> . @prefix ex: <http://example.org/tokyo/terms/> . <#A00102> ex:日時 "2015年9月3日午後4時" ; ex:計測時間 "1時間" ; ex:計測地 <http://example.org/tokyo/place/麻布十番> ; ex:平均値 "18.7km/h" .
恒久的なURIの設計
ブックマークしておいたページや検索結果を開こうとして「404 Not Found」エラーになってしまい舌打ちした経験は誰もが持っていることでしょう。URIは可能な限り変更しなくてよいように設計する必要があります。RDFの場合も同じです。
恒久的なURIとするための注意点をいくつかあげておきましょう。
組織名
URIは分散型に権限を移譲して管理することになるので、URIの一部にその管理主体の名前を入れることが少なくありません。たとえばexample大学理工学部情報学科の山田研究室の交通調査プロジェクトなら、次のような具合です。
例6
http://st.example.ac.jp/infoscience/~yamada/traffic#A00102
しかしこれでは、学科名がコンピュータ学科に変わったり、山田先生が別の大学に移ったりした場合に、同じURIを維持することが困難でしょう。ドメイン名のようにそう簡単に組織名と違うものを用いるわけには行かないものもありますが、組織名など変更の可能性がある要素はURIに含めないのが賢明です。
どうしても組織名を使わざるを得ない時は、purl.orgのような転送サービスを利用する手もあります。たとえば次のようなURIにアクセスすると、上のURIに転送されるように設定するというものです。
例7
http://purl.org/net/myproject/traffic#A00102
こうしておけば、何らかの理由で終点URIを変更する場合も、転送設定を変えればURIは迷子になりません。
バージョン番号
情報内容が更新されるものである場合、どのバージョンのものかを示す手段が欲しくなることがあります。これは語彙定義でプロパティの制約を変更したりクラスの階層構造を変えたりといった変更がある場合などが想定されるケースですが、個別データでも組織や活動の情報で内容が大きく変わる(住所が移転するとか上部組織が変わるとか)こともあり得るでしょう。このとき、URIにバージョンを含めるべきでしょうか。
古い情報と区別するという意味ではバージョンを含めた識別子が望ましいこともあります。一方でそのURIを利用する立場からすると、これまで使っていたものと違うURIが出てきては困ることもあります。語彙URIが変わると、基本的に同じ意味のプロパティなのに異なるURIのものができてしまい、データの整合性や検索に支障をきたします。そのため、たとえば当初実験プロジェクトとしてスタートしたFOAFはURIに"0.1"というバージョンを含めていましたが、語彙が普及したためにURIを変更するわけには行かなくなり、永遠のベータ版URIのようになっています。
例8
http://xmlns.com/foaf/0.1/name
一つの方法は、バージョンや日付を含むURIでそれぞれの情報を管理しつつ、それらを含まない恒久URIを用意し、そこからは(エイリアス、あるいはシンボリックリンクを用いて)常に最新版が取得できるようにすることです。たとえばW3Cの標準仕様文書は草案から何度も改訂を重ねて勧告に至り、場合によっては新しいバージョンに改定されたりしますが、最新版には常に同じURIでアクセスできます。HTML仕様でいえば
例9
http://www.w3.org/TR/html/
は現在ではHTML5の勧告である
例10
http://www.w3.org/TR/2014/REC-html5-20141028/
と同一の文書を指しているのです。こうすれば、安定したURIを使いたいときは前者を、バージョンごとに異なる情報として管理したい場合は後者を利用するといった選択が可能になります。
フォーマットと拡張子
RDFは複数の構文で記述することができ、また複数の構文によるデータを公開することも推奨されています。このとき前に述べたハッシュ型URIを、相対URIで、しかも基底URIなしに記述していると、ファイル(構文)ごとに異なるURIができてしまいかねません。たとえばTurtle形式のデータをtraffic.ttl、RDF/XML形式データをtraffic.rdfで公開しているとき、基底URIがないと
例11
http://example.org/tokyo/survey/traffic.ttl#A00102 http://example.org/tokyo/survey/traffic.rdf#A00102
というURIができてしまいます。RDFデータをファイルで公開する場合は原則として基底URIを記述し、できるだけ拡張子なしでもそのファイルにアクセスできるようにしましょう。上記の場合、.../survey/trafficにアクセスしたアプリケーションが、Turtleファイルを希望(accept)すればtraffic.ttlを、RDF/XMLを希望すればtraffic.rdfを返すという内容折衝(content negotiation)ができるようにサーバーを設定します。
リンクするデータ、ふたたび
第1回の最後にティム・バーナーズ=リーのリンクするデータの4原則を紹介しました。ここまで検討してきた考え方で、この原則に則ったデータの記述ができているでしょうか。これを確認しながら、「リンクするデータ」の考え方をおさらいしておきましょう。
1. ものごとをURIで名前付けする
これは何度も繰り返した基本なのでOKですね。データの中のAnything(実体、エンティティ)を把握し、それをURIで名前付けします。空白ノードではなくURIにすることが大切です。
2. URIはhttp:スキームにする
これも、今回の例はみなhttp:スキームなので大丈夫です。
そもそもhttp:じゃないURIを使うことってあるのか?と思われるかもしれませんが、たとえばデジタルオブジェクトの識別子であるDOIの場合、info:スキームにdoiスペースを登録し、これを用いようとしていました。
例12
info:doi/10.1038/nature13316
しかしこれではこのDOIで識別される論文にウェブからアクセスすることができないので、現在は次のようにhttp:スキームを用いることが普通になっています。
例13
http://dx.doi.org/doi:10.1038/nature13316
同様に書籍を識別するISBNの場合、urn:isbn:4003220625のようなurn:スキームのURIが登録されています。DOIと違ってISBNの場合はhttp:による公式なURIが定まっていないため、せっかくの識別子がうまくURIとして利用できない状況です。
現状でISBNを「リンクするデータ」として扱うには、「URIの再利用と自前のURI」でも述べたように独自のURIでISBNを表現した上でNDLサーチの書誌などと関連付けるか、RDF Book Mashupのような非公式リゾルバを用いることになるでしょう。
3. URIが辿られたら有用な情報を返す
ハッシュ型URIを用いてURI本体からRDFファイルが得られるようになっていれば、これも大丈夫です。拡張子なしでもアクセス可能に設定しておかないと、URI本体でのリクエストが「404 Not Found」となってしまいますから注意して下さい。スラッシュ型URIの場合は、個々のURIごとにファイルを用意するか、URI階層の上位をアプリケーションにして、受け取ったURIをパラメータとして扱えば、リクエストに応じて適切な情報を返すことができます。
自組織で管理していないコードをURI化したとき、それに対して有用な情報を返せるようにするのは手間のかかる追加作業です。シンプルでも構わないので、各コードのラベルとコード全体を説明する情報へのリンクを記述し、全体説明にコード管理主体へのリンクを含めておくとよいでしょう。
例14
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> . #コード全体の説明 <http://example.org/code/industry> rdfs:label "日本標準産業分類" ; rdfs:seeAlso <http://www.e-stat.go.jp/SG1/htoukeib/BunruiFocus.do> . ... #それぞれのコード <http://example.org/code/industry#1022> rdfs:label "ビール類製造業" ; rdfs:isDefinedBy <http://example.org/code/industry> .
4. ほかのURIへのリンクを加える
グラフをたどっていくときに、値がリテラルだとそこで行き止まりです。「識別されるべきAnything」にはURIを与え、さらにその説明を他のURIに結びつけることで、データが次々につながって行く「リンクするデータ」となります。

四半世紀前に誕生したWWWは、HTMLで記述された情報を中心としたハイパーリンクによる「文書のウェブ」として発展してきましたが、バーナーズ=リーの最初の提案文書Information Management: A Proposalの冒頭に掲げられた図は、文書だけでなく"Hypertext"という概念やCERNの組織階層、Tim Berners-Leeといった人までがつながる情報空間を描いていました。リンクするデータのが織りなす「データのウェブ」が「文書のウェブ」に加わることで、このバーナーズ=リーの構想した世界が、一歩近づいてきます。
「データのウェブ」の力は、「文書のウェブ」と同じくリンクをたどって新たな情報を発見できるところにあります。誰がどんなことをデータとして記述してもよいRDF、そしてデータがリンクを介して未知のデータに出会うワンダーランド。リンクするデータは、anythingとanythingをつなぐ「不思議の国のデータ」だといってもいいでしょう。
Linked Open Data・RDFの活用ソリューションならインフォコム


