





04/10
IIIFマニフェストと注釈
神崎 正英
IIIFマニフェストで用いられる@typeの値は、多くがsc:という接頭辞で始まっています。これはShared Canvasの略に由来するもの。カンバスという抽象モデルを用いて、異なる組織やアーカイブの資料を共有可能にしようという「共有カンバス」が、IIIFの前身です。そのカンバスは、画像だけでなくテキスト、そして音声や動画も扱う、資料提示の基盤となります。
共有カンバスと注釈
IIIFマニフェストの中心となるオブジェクトはカンバスです。前々回にも触れたように、カンバスのimagesプロパティ値となる配列要素は、画像自身ではなく注釈(oa:Annotation)で、その注釈のresourceが画像となっています。これは、資料オブジェクトの画像に異なるサイズやフォーマットがある場合、ビューアの環境やズームなどに合わせて適切なものを選び、カンバス上に「描く」という考え方を取っているためです。
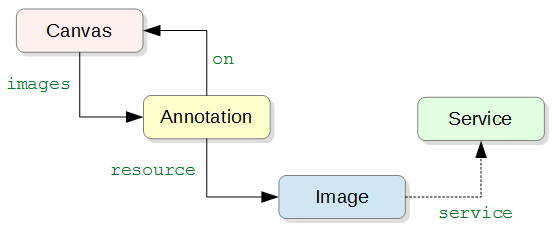
カンバスには、画像だけでなく他のオブジェクトも重ねて「描く」ことができます。また描く対象はカンバス全体にかぎらず、その一部であっても構いません。これを利用して、画像の部分に対するテキスト説明なども、やはりカンバスへの注釈として表現できるようになっています(後述)。
"空白ページ"への注釈
ウェブ上の注釈は、情報の共有や連携の仕組みとしてWWW誕生の直後から関心が持たれてきましたが、標準化に向けての転機になったのは、2009年のOpen Annotation Collaborations(OAC)発足です。それまでウェブ文書を中心に考えられることが多かった注釈対象を、技術の動向を踏まえて画像などのメディア資源にも広げ、ティム・バーナーズ=リーが提唱して注目されていたLinked Data(リンクするデータ)の考え方をも取り入れようという試みがスタートしました。モデル表現の基本にはRDFが据えられます。
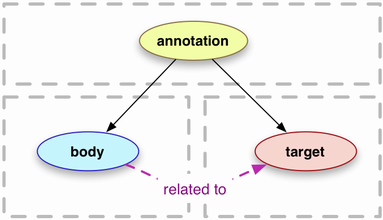
OACのメンバーでもあったロバート・サンダーソンは、2010年末に欧米の研究者や図書館関係者を集めて開催されていた写本デジタル化の共有技術研究会において、EmptyPagesというアイデアを発表します。古い写本は、ページの一部が抜け落ちてしまったり、一つの写本がばらばらになって複数の機関で保有されていたり、それぞれデジタル化の精度が異なったりと、単純に扱えない要素が多数あるため、抽象的な"空白ページ"を用意し、そこにデジタル画像やテキスト転写などを表示して、共有化を図ろうというのです。
空白ページの「ビュー」と画像やテキストは、「注釈」によって結び付けられます。Open Annotationの応用です。
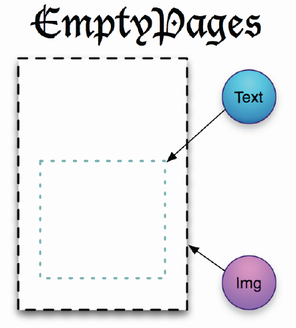
この時点ですでに、ビューを並べる「シーケンス」、また階層構造などを記述する「レンジ」が提案に含まれていました。
共有カンバスのモデル
Open Annotationが共有注釈(Shared Annotation)を強く打ち出していたこともあってか、この"空白ページ"は共有カンバスと名付けられ、翌2011年春にSharedCanvasと銘打った論文が出されます。6月にはshared-canvas.orgを立ち上げて本格的な議論を開始、2012年6月には仕様のβ01版が作られました。
次の図は、β01版仕様書に掲載された概念図で、その後も共有カンバスにおける「注釈」の考え方を示すために用いられたものです。
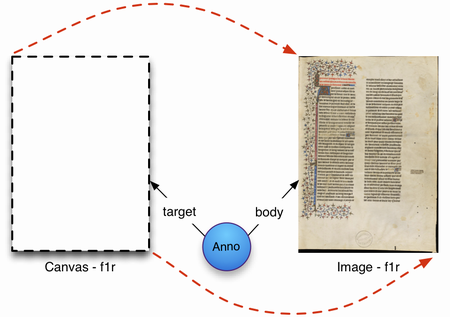
ここでは、テキストはひとまず措いて、画像そのものを注釈として扱う考え方が提示されています。図をよく見ると、カンバスが注釈(Anno)のtargetに、画像がそのbodyになっていますね。これは、図2に示したOpen Annotationの基本モデルそのものであることが分かるでしょうか。
Open Annotationの注釈モデルは、注釈の対象と内容が異なるところにあってかまわないという点を重視していました。SharedCanvasに当てはめると、注釈対象であるカンバス(つまりビューア)は、注釈内容の画像とは独立して扱われます。画像を保持する機関が専用のビューアを用意するのではなく、共有されるカンバスにさまざまな画像(およびテキスト)を描くことができるというわけです。
共有カンバスは、Open Annotationに従って、RDFをそのまま(Turtleなどで)記述していました。注釈=カンバスはRDFグラフとして表現できれば、単独でもまったく別のリソースと組み合わせても構わないことになるのですが、ツールで利用するにはカンバスを順番に並べるなどの構造化が必要なので、リスト(sc:AnnotationList)が併せて定義されました。そして、"空白ページ"で想定されていたシーケンスやレンジをリストと組み合わせられるように、これらをまとめる容れ物としてマニフェストが加えられています。
IIIFとJSON-LD
これらと並行して、「画像配信のための相互運用可能なフレームワーク」であるIIIFの活動が2011年末に始まります。画像配信サービスのAPI(現在の画像API)が検討され、さらにメタデータ記述のデータモデルとしてShared Canvasが挙げられていました。
2013年2月にIIIFのもとで1.0となった共有カンバス仕様は、同年6月にはMetadata APIに発展します。このバージョン0.9の告知では、資料の公開やビューア開発を容易にするために、共有カンバスモデルから次の点を改良したと述べられています。
- JSONを用いた単一の記述構文の採用。これは〔ちょうど草案がW3Cから出されようとしていた〕JSON-LDを利用していて、RDFに準拠している
- モデル内におけるリソースの、単一の階層の配置
- 1回のリクエストでどれだけの情報を取得すべきかを、実装とユースケースに基づいて明示
- 各リソースのURIパターンの推奨(必須ではない)
JSON-LDによる記述
ウェブ・アプリケーションの開発が盛んになり、データはJSONでの提供が期待されるようになっていました。ただJSONのキー(プロパティ)はローカルな名前でしかなく、特定の約束を前提にしたやり取りを越えてデータを広く共有するためには、グローバルな名前(URI)を組み込む手段が必要でした。
JSON-LDは、コンテクストという仕組みを導入することによって、ローカルな名前をURIとして解釈可能にする方法です。RDFをJSONで記述する構文の一つとして2010年頃に提案され、2012年にはW3CのRDF WGで正式に仕様策定を進めることになっていました。RDFによるモデルとして出発したSharedCanvasに、このJSON-LDを適用することで、JSON構文での記述が可能になるわけです。
図4に示したSharedCanvasのモデルをそのままJSON-LDで表現すれば、次のようになるでしょう。
例1
{
"@type": "oa:Annotation",
"motivation": "sc:painting",
"body": {
"@id": "http://codh.rois.ac.jp/pmjt/iiif/200014778/200014778_00008",
"@type": "dctypes:Image",
"format": "image/jpeg",
},
"target": {
"@id": "http://codh.rois.ac.jp/pmjt/iiif/200014778/canvas/00008",
"@type": "sc:Canvas",
"height": 3744,
"width": 5616,
"label "Page 8"
}
}
ただこれではカンバスと画像が別の枝に分かれてしまい、「カンバス上に画像を描く」という構造と直感的にマッチしません。そこでJSONを組み立て直し、カンバスの中に注釈が入る形が考案されます。
例2
{
"@id": "http://codh.rois.ac.jp/pmjt/iiif/200014778/canvas/00008",
"@type": "sc:Canvas",
"height": 3744,
"width": 5616,
"label "Page 8",
"images": [
{
"@type": "oa:Annotation",
"motivation": "sc:painting",
"resource": {
"@id": "http://codh.rois.ac.jp/pmjt/iiif/200014778/200014778_00008",
"@type": "dctypes:Image",
"format": "image/jpeg",
},
"on": "http://codh.rois.ac.jp/pmjt/iiif/200014778/canvas/00008"
}
]
}
例1と例2を、注釈を表すオブジェクト(oa:Annotationタイプ)に注目して比べると、target、bodyがそれぞれon、resourceに変わっただけであることが分かるでしょう。そしてtarget(on)の値、つまりカンバスは、入れ子オブジェクトをやめて外側に移動しました。その上で、直感的な(しかし紛らわしい)imagesプロパティを用いて(かつ画像は複数あり得るということで配列として)注釈と結びつけ、現在のIIIF表現APIの原形ができあがったのです(9月にはMetadata API 1.0が公開されています。そして次のバージョンが翌2014年に5月に出されたとき、Presentation API 2.0と名称が変更され、コンテクストURIも現在のものとなりました)。
JSON-LDはコンテクストを用いて解釈することでRDFグラフを得ることができます。上記のメタデータAPIモデル(=IIIF表現APIモデル)からは、実はOpen AnnotationそのままのRDFが得られるようになっているのです(Open Annotationは今年2月にWeb AnnotationとしてW3C勧告となりました。IIIFマニフェストから得られるRDFは、この仕様にも準拠しています)。
外部注釈の追加
さて、"空白ページ"の時から、画像とテキストの両方を注釈としてカンバスに重ねるという考えに基づくモデルが提示されてきたわけですが、注釈対象と注釈内容の関係をimagesとしてしまったので、その中にテキストを含めるわけには行きません。そこで、テキストなど画像以外の注釈内容は、otherContentという別のプロパティで外部注釈として関連付けることになりました(Metadata APIの0.9の時点では、resourcesというプロパティで両者を一括して扱っていたのですが、画像配信としての分かりやすさを優先したのか、1.0で分離されました)。
ただしotherContentの値は、注釈(oa:Annotation)の配列ではなく、注釈のリスト(sc:AnnotationList)の配列です。さらにこの注釈リストの実体(JSON)はマニフェスト内に埋め込むのではなく、別ファイルに記述してURIで参照することになっています。
これはビューアが素早く画像を利用者に提供できるようにするとともに、テキストなどの注釈が追加・編集されても画像のマニフェストは変更しなくて済むようにという狙いからだとされています。また、画像提供者とテキスト提供者は同一とは限らないという点も重要でしょう。複数の注釈を記述できる注釈リストをさらにotherContentで配列にするという一見冗長な構成によって、異なる注釈セットを組み合わせた利用が可能になっているわけです。
カンバスから外部注釈へのリンク
例2のカンバスに対する注釈リストを、http://example.org/annolist.jsonに用意したとしましょう。カンバスからは、次のようにしてこの注釈リストを参照します。
例3
{
"@id": "http://codh.rois.ac.jp/pmjt/iiif/200014778/canvas/00008",
"@type": "sc:Canvas",
"height": 3744,
"width": 5616,
"label "Page 8",
"images": [
...
],
"otherContent": [ "http://example.org/annolist.json" ]
}
otherContentの配列要素には、上記のようにURIを直接書く他、sc:AnnotationListタイプを持つオブジェクトとして記述することもできます。
例4
"otherContent": [
{
"@id": "http://example.org/annolist.json",
"@type": "sc:AnnotationList"
}
]
わざわざオブジェクト型を用いる必要はないような気がしますが、Miradorはこちらしか認識できず、URIを文字列として列挙するだけではテキスト注釈を表示してくれないようです。
注釈リストの記述
注釈リストの記述は、IIIF表現APIの他のJSONファイルとほぼ同様です。
| プロパティ名 | 値の内容 |
|---|---|
@context | 表示APIのコンテクストのURI |
@id | 注釈リストのID。通常は注釈リストのJSONファイルを取得できるURI |
@type | 注釈リストを示す型で、値は常にsc:AnnotationList |
resources | リストが持つ注釈の配列(注釈自身が持つプロパティと異なり複数形) |
resourcesの配列要素となる注釈は、画像の場合と基本的に同じです。カンバスに表示するのであればテキストでも何でもmotivationは常にsc:painting。そして具体的な注釈内容をresourceプロパティ値として記述します。カンバスは同じファイルには含まれないわけですが、onプロパティ値としてURIを記述することによって結び付けられます。
画像の場合は外部にあるリソースを注釈から参照することになりますが、テキスト注釈の場合は、このJSONファイル内に直接記述できる方が便利です。IIIF表現API仕様では、これを埋め込みコンテンツと呼び、cnt:ContextAsTextタイプのリソースとして記述するとしています。テキストはcharsプロパティの値になります。
例5
{
"@context": "http://iiif.io/api/presentation/2/context.json",
"@id": "http://example.org/annolist.json",
"@type": "sc:AnnotationList",
"resources": [
{
"@type": "oa:Annotation",
"motivation": "sc:painting",
"resource": {
"@type": "cnt:ContentAsText",
"chars": "蝶と蜻蛉が描かれ...",
"format": "text/plain",
},
"on": "http://codh.rois.ac.jp/pmjt/iiif/200014778/canvas/00008"
}
]
}
cnt:ContextAsTextは見慣れないタイプですが、先ごろW3CのノートになったRepresenting Content in RDF 1.0で定義されているものです。formatをtext/htmlとすれば、テキストにマークアップを含めることができます。
埋め込みコンテンツの他に、外部リソースの動画や音声を注釈とすることも可能です。その場合は@typeの値をdctypes:MovingImage、dctypes:Soundとし、charsの代わりに@idでメディアファイルのURIを示します(画像の場合と同じ形になります)。
カンバスの部分への注釈
注釈の重要な用途の一つが、画像の部分についての説明でしょう。これは前回レンジの記述で取り上げた、「カンバスの部分の参照」によって表現します。カンバスURIに、対象範囲の座標を示すメディアフラグメントを加えるのです。
例6
{
"@type": "oa:Annotation",
"motivation": "sc:painting",
"resource": {
"@type": "cnt:ContentAsText",
"chars": "蜻蛉 一富士二鷹 人こころあきつむしともならばなれ...",
"format": "text/plain",
},
"on": "http://codh.rois.ac.jp/pmjt/iiif/200014778/canvas/00008#xywh=2870,857,1016,745"
}
こうした注釈を理解できるツールなら、カンバス上に画像と注釈テキストを重ねて表示することで、画像の座標部分への注釈を表現してくれるでしょう。

IIIF 3とA/V
最後に、次期バージョンIIIF 3についてコミュニティで進められている議論の中で、音声動画を扱えるようにというA/V技術仕様グループの動きを簡単にとりあげておきましょう。これはカンバスに「描く」主たる注釈内容を、(imagesとして特別扱いの)画像だけでなく(otherContent扱いされている)音声や動画にまで拡張しようということで、2016年春のロンドンでのワークショップ辺りから検討が始まっているものです。
詳細はまだまだこれからという段階ですが、これまでの議論の中で打ち出されてきた方向性としては、次のようなものがあります。
@type、@idというJSON-LD特有のプロパティや、oa:Annotation、sc:CanvasのようにRDF的な接頭辞を持っている値を、シンプルにtype、id、Annotation、Canvasなどとする(JSON-LDコンテクストを書き換えることで、同じ意味を引き継ぎます)images、otherContentという区別をなくしてcontentに一本化し、その値をAnnotationPageの配列とする(現在のsc:AnnotationListと同等)。AnnotationPageはitemsプロパティを持ち、その値をAnnotationの配列とする- カンバスの基本プロパティとして、
width、height対の他にdurationを加え、少なくともいずれかを必須とする
AnnotationPageを別ファイルにすることを求められないので、同じJSONの記述中に画像、音声、動画、そしてテキスト注釈も一緒に含めることができます。仮に上の形で仕様がまとまるとすれば、動画へのテキスト注釈(いや、カンバスに動画とテキスト注釈を重ねたもの)は次のような具合になるでしょう。
例7
{
"type": "Canvas",
"id": "http://example.org/tea-sprout/canvas",
"label": "お茶、新芽の成長",
"duration": 9,
"content": [
{
"id": "http://example.org/tea-sprout/content-1",
"type": "AnnotationPage",
"items": [
{
"id": "http://example.org/tea-sprout/content-1-1",
"type": "Annotation",
"motivation": "painting",
"body": {
"id": "http://example.org/media/growing-tea-sprout.mp4",
"type": "Video"
},
"target": "http://example.org/tea-sprout/canvas"
}
]
},
{
"id": "http://example.org/tea-sprout/content-2",
"type": "AnnotationPage",
"items": [
{
"id": "http://example.org/tea-sprout/content-2-1",
"type": "Annotation",
"motivation": "painting",
"body": {
"type": "TextualBody",
"value": "ここに注目"
},
"target": "http://example.org/tea-sprout/canvas#xywh=percent:42.81,40.61,18.53,35&t=1,2"
},
]
}
]
}
この動画注釈を試しに実装してみると、次のようなイメージになります。
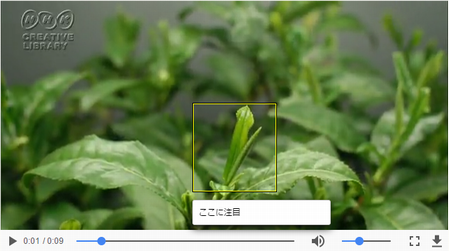
仕様が固まらないうちにあまり先走っても仕方ありませんが、音声、動画も扱えるとなると、資料提供の方法としてIIIFからますます目が離せなくなりそうです。
Linked Open Data・RDFの活用ソリューションならインフォコム


