





10/01
モノのウェブ、そしてリンクするデータ
多様なデータが連動する「モノのウェブ」
さまざまなものにIPアドレスを持つセンサーやRFIDタグを付与し、インターネットに組み込んでつながりをもたせようという「モノのインターネット」(Internet of Things)が注目されています。これをサービスという観点で捉えると、その膨大なデータを相互運用可能な形で扱える標準的なウェブ技術が不可欠です。そのための共通の枠組みを目指して議論しようということで、「モノのウェブ」(Web of Things)をテーマにしたW3Cのワークショプが今年(2014年)の6月に開催されました。
ワークショップではセキュリティ、UI、スケーラビリティなどいくつかの討議の柱が掲げられましたが、その一つに「セマンティクスの役割」という分野があります。センサーなどの入力を処理するためにはそのコンテクストを正しく理解する必要があり、多様なデータの相互運用にはセマンティクスが鍵となる、という問題意識のもとに、数多くの発表やデモが行なわれました。
この発表の一つ、"Semantic Modeling of Smart City Data"は、EUのスマートシティプロジェクトであるCityPulseにおいて、多種混合データをどのように連携させるかを検討しています。スマートシティのデータは、交通、行政サービス、イベント、市民動向、健康関連など多岐にわたり、それぞれが動的かつ大量に生み出されます。これらのデータを組み合わせ、そこから有益な情報や知見を得るうえで課題になるのは、データの計測単位やフォーマットから品質、プライバシー要件に至る違いを踏まえた相互運用のモデルです。
彼らの表現を借りれば、スマートシティは「つながりあうデジタル層に向けてサイロを取り去る(abstracts silos moving towwards a connected digital layer)」ことを目指します。ここでのサイロとは、生成されたデータを共有・再利用できなくしてしまう窓のない貯蔵庫のこと。さまざまなデータを連動させて有益な情報を得るためには、このサイロを開いて(壁を取り去って)データを公開し、さらにそれらが相互運用可能な共通の土俵=モデルを作る必要があるのです。
領域を超えたデータの共有・再利用
さまざまな領域のデータを扱う枠組み
データのサイロを開け放ち相互運用するために、どのようなモデルがあれば共通の土俵となるでしょうか。たとえば「9月1日の午後1時から1時間半、芝新堀町で車の走行速度を計測したところ、平均値は時速25.4キロメートルだった」という交通計測記録(レコード)があるとしましょう。このレコードのデータを属性(プロパティ)と値の関係で示せば次のようになります。
| プロパティ名 | 値 |
|---|---|
| 日時 | 2014年9月1日午後1時 |
| 計測時間 | 1時間半 |
| 計測地 | 芝新堀町 |
| 平均値 | 25.4km/h |
複数箇所で複数回にわたって計測したデータは、プロパティを列とし、それぞれの計測レコードを行とした表で集計することが多いでしょう。データベースに納める場合、通常はレコードを識別するために主キーとなるIDを与えます。
| ID | 日時 | 計測時間 | 計測地 | 平均値 |
|---|---|---|---|---|
| A00101 | 2014年9月1日午後1時 | 1時間半 | 芝新堀町 | 25.4km/h |
| A00102 | 2015年9月3日午後4時 | 1時間 | 麻布十番 | 18.7km/h |
| ... | ... | ... | ... | ... |
この表において、個々のセルに示されるデータは、「あるIDのレコードにおけるあるプロパティの値」と示すことがきます。たとえば「ID"A00101"のレコードの"平均値"は"25.4km/h"である」という具合です。ここで自然言語になぞらえてIDを「主語」、プロパティ名を「述語」、その値を「目的語」としましょう(3つの要素なのでこれらをまとめて三つ組=トリプルと呼びます)。主語と目的語をノードとし、述語を矢印として両者を結べば、次のような有向グラフによってデータを表現できます。

他のプロパティ/値も同様にトリプルの有向グラフで表現可能です。このとき、それぞれの主語はいずれも"A00101"で同じなので、一つのノードにまとめたグラフが描けます。
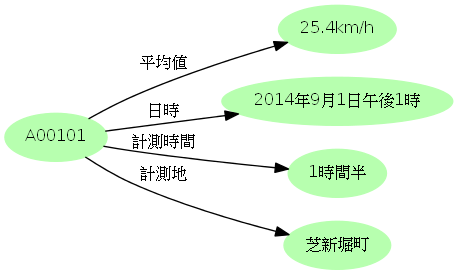
このように共通のノードを介してトリプルを連結することで、複雑な情報も有向グラフで表現できます。また逆に、込み入った関係も全て主語―述語―目的語のトリプルに還元でき、同じシンプルな枠組みを用いて処理することが可能になります。交通、行政サービス、健康関連など異なる分野のデータの記述にはそれぞれに適した仕組みが必要ですが、これらを有向グラフで表現すれば、全てをトリプルという共通モデルで考えることができるのです。
名前のスコープ
さて、交通計測記録の例ではプロパティ名を「平均値」、IDを「A00101」などとしていましたが、こうした名前やIDはその記録を記した表の範囲(スコープ)でしか通用しません。別の計測記録では「平均」というプロパティ名を使うかもしれませんし、「A00101」という同じIDが全く別の記録で用いられている可能性もあります。
異なる情報源のデータを相互運用させるためには、どこで用いても同じもの/ことを示す名前が必要です。一つの都市においてですら、多様なデータのプロパティ名やIDを全て一括管理するのは容易ではありません。いわんや、別の都市のデータあるいは異なる領域のデータとの連動においてをや。スコープが広がれば広がるほど、名前の問題は手に負えなくなってしまいます。
幸いウェブには、URI(Uniform Resource Identifier)というグローバルなスコープの名前付けシステムがあります。特にhttpスキームのURIは、ドメイン名の割り当てを登録管理し、ローカル部分の名前はドメイン管理者に委譲するという分散システムなので、グローバルに一意な名前を一極集中することなく割り当てることが可能です。
たとえば交通計測記録のプロジェクトが<http://example.org/tokyo/>を管理しているとすれば、ID「A00101」は<http://example.org/tokyo/survey/traffic/A00101>というURIにしてもよいでしょう。述語も、曖昧さがないようにURIを用います。「平均値」は<http://example.org/tokyo/terms/平均値>とするなどです。

有向グラフのトリプル要素をURIで名前付けし、データのセマンティクスを明確にする仕組みがRDF(Resource Description Framework)です。RDFのトリプルを集めたものをRDFのグラフと呼びます。
RDFグラフとして記述することよって、どんなデータでもトリプル+URIという共通の土俵に乗せて扱えます。この例の計測記録は、ニューヨークの交通調査やロンドンの健康データとも組み合わせることが可能になるのです。
リテラルと空白ノード
前述のとおりRDFで用いる名前はURIが基本ですが、「25.4km/h」という値はどうでしょう。IDはレコードという"実体"、平均値はそのレコードにおける測定値の平均という"プロパティ"と、それぞれ名前をつけてシンボル化しなければコンピュータで直接扱えないものを指していました。しかし「25.4km/h」は測定結果から得られるデータそのものですから、それ自身が処理対象です。RDFではこのような値そのものを表す文字列を「リテラル」と呼びます。RDFトリプルの目的語は、URIでなくリテラルとすることもできます。

ところでこの「25.4km/h」は、「25.4」という数値と「km/h」という単位が一つのリテラルの中に詰め込まれています。これでは、データを統計解析したりグラフ化しようというときにプログラムが数値処理できません。
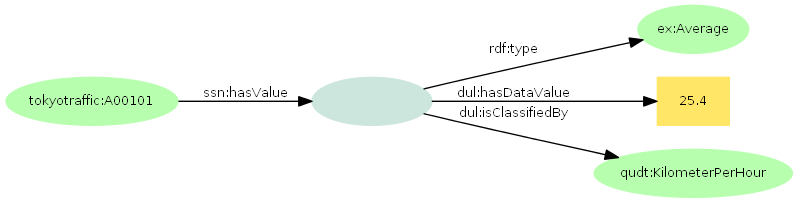
RDFでこのようなデータを扱う方法の一つは、数値と単位をそれぞれ別のトリプルで表現し、それをまとめるノードを仲介として主語(レコードID)と結びつけるというものです(以下の図では一部のURIをterms:平均値などの形で短縮表記します)。

このとき、この仲介をするノードは「A00101」の「平均値」の目的語としてはじめて有用な意味を持ち、単独で名指す(URIでグローバルに名付ける)必要はほとんどありません。こうしたURIで名前付けないノードを、RDFでは「空白ノード」と呼びます。空白ノードは、数値と単位のほかにも、姓と名、住所(都道府県、市町村、番地)といった一組の値をまとめて構造化するときにしばしば用いられます。
名前の共有とLinked Data
語彙の共有
プロパティ名をURIで表現すれば曖昧さはなくなりますが、計測記録がそれぞれ<http://example.org/tokyo/terms/平均値>のように独自の述語を用いていては、データの共有・再利用は手間がかかってしまいます。多くのデータに共通するプロパティは、同じ名前(URI)の述語で記述できる方が具合がよいでしょう。
スマートシティの例では、W3CのSemantic Sensor Network XGで検討、報告されたセンサーネットワークの記述語彙(プロパティ名などの定義)を取り上げています。この語彙を中心にして先ほどの交通計測記録を表現すれば次のようになるでしょう。グラフの形はほぼ同じですが、公開された語彙を述語に用いているので、相互運用性が高まるはずです。
センサーデータの的確な記述にはやや特殊な語彙が必要になりますが、作品などのカタログ的情報ならDublin Core、人に関する情報ならFOAFといった語彙がほぼ定番で使われ、ほとんどのシステムで理解される共通語彙となっています。統計データなら今年1月にW3C勧告となったData Cube語彙が利用できます。
また、幅広い分野をカバーするワンストップ語彙Schema.orgは、主要検索エンジンの支持もあって広く用いられるようになってきました。そのほかどのような語彙が使えるか調べたい場合は、Linked Open Vocabularies (LOV)が検索手段を提供してくれます。
ノード名の共有
グラフがつながるためには、主語や目的語となるノードの名前が共有されなくてはなりません。さまざまな分野において、こうした名前を一貫した形で運用するために標準コードや統制語彙、典拠ファイルが構築されてきました。これらをURIとして用いることができれば、RDFによるデータの連携が大きく進みます。
たとえば交通計測記録の例で「計測地」の値は「芝新堀町」となっていましたが、世界規模の地名データベースであるGeoNamesでは芝新堀町に"1852609"というIDが与えられています。GeoNamesはさらにこのIDをURI化しており、<http://sws.geonames.org/1852609/>でこの場所を識別することが可能です。

ノードの名前に標準コードのURIを用いることで、曖昧さがなくなるだけでなく、同じ値を持つ別のRDFグラフとのつながりが生じます。地名URIを介して交通計測記録と住民サービス、イベントなどのデータが連結されるのです。
リンクするデータへ
URIがhttpスキームであれば、アプリケーションはサーバーにリクエストを送ってそのリソース表現を取得することができます。GeoNamesの場合、URIのリソース表現にもRDFグラフが記述されており、gn:parentFeatureという述語の目的語は上位区分である東京のURIが、またgn:nearbyFeaturesの目的語には近隣の地名IDを記したRDFファイルのURIが示されています。つまりGeoNamesのURIは、場所の識別だけでなく、その場所に関連する情報へのリンクとしても機能しているのです。
このように、識別する名前であるURIから関連情報の取得もできるようにしたものをリンクするデータ(Linked Data)と呼んでいます。WWWの創始者であるティム・バーナーズ=リーが2006年に公開したリンクするデータの4原則は、次のようにしてデータがつながるようにすることを提唱しています。
- ものごとをURIで名前付けする
- これらの名前を調べて訪ねる(参照解決する)ことができるように、
httpスキームのURIを使う - 名前付けしたURIがたどられたら、有用な情報を返す
- ほかのURIへのリンクを加えて、より多くのものごとを見出せるようにする
標準コードや統制語彙にURIを与え、関連記述と合わせてLinked Data化した例は、国立国会図書館のウェブ版典拠(Web NDLA)、WikipediaのRDF版であるDBpediaなど、数多く登場しています。そしてこれらのデータセットがまた相互にリンクすることで巨大なRDFグラフが形成され、「データのウェブ」が広がっているのです(前述のGeoNamesもその一部です)。
「モノのウェブ」においても、多様なレコードをそれぞれアクセス可能なURIで識別し、いずれかの値をGeoNamesやDBpediaに関連付けておけば、プロジェクトやサービスの範囲を超えて世界中のデータとつながっていくことになります。スマートシティの発表ではこれを"Linked Stream Processing"と呼び、ウェブ全体に広がる情報とのつながりによってより豊かで適切な情報記述が可能になる、とその狙いが述べられていました。ふたたび発表スライドの一部を借用すれば、これは次のような関係として表すことができるでしょう。
モノのウェブ = デバイス/サービスのウェブ + データのウェブ
ウェブとは、リンクのつながりによって新たな発見と価値を生み出してきた場です。HTMLを中心にした「文書のウェブ」、リンクするデータが織りなす「データのウェブ」、そしてそれが多様なデバイスやサービスと結びつく「モノのウェブ」。私たちのウェブは今、その領域を大きく広げて発展しようとしています。
Linked Open Data・RDFの活用ソリューションならインフォコム


