





01/27
RDFを記述する構文
神崎 正英
RDFのモデルと構文
情報をコンピュータに理解しやすく、共有・再利用しやすい形で記述するための枠組みとして、RDF(Resource Description Framework)を紹介してきました。これはデータを「主語」「述語」「目的語」の3要素で構成されるトリプルの組合せとして表現し、それぞれのトリプルを有向グラフで表すというものでした。

このようなノード(円もしくは長方形)を矢印で結んだ図は人間が見て関係を理解するためには分かりやすいですが、データ表現としてコンピュータが直接扱うのには向いていません。RDFで記述したデータ(グラフ)をコンピュータ処理させるためには、この有向グラフの関係を文字列として表現する具象構文が必要です。
トリプルの直訳:N-Triples
RDFのトリプルは主語(S)、述語(P)、目的語(O)の3つでできており、それぞれはURI、リテラル、空白ノードのいずれかです。少なくともURIとリテラルは文字列で表現できますから、たとえばURIは<>で、リテラルは""で囲むという約束で区別して、SPOの順番に並べれば、上の図を表現する構文とすることができます。並べるだけではトリプルが複数連続するとどれが主語なのか分からなくなってしまうので、SPOの最後をピリオド(.)で区切ることにします。
例1
<http://example.org/tokyo/survey/traffic/A00101> <http://example.org/tokyo/terms/平均値> "25.4km/h" .
この最もシンプルなトリプルの記述構文をN-Triplesと呼びます。単純なだけにコンピュータの処理も効率的で、大量のRDFデータを扱うためによく用いられる構文です。
しかしURIとリテラルが記述できるだけでは空白ノードが宙に浮いてしまい、次のグラフを表現することができません(これまで同様、以下の図では一部のURIをterms:平均値などの形で短縮表記します)。


空白ノードは名前がないのでそのままでは文字列で表現できないわけですが、N-Triplesでは空白ノードにも仮の名前(空白ノードID)を与えることで、文字列構文で記述するようにしています。空白ノードIDは先頭を_:とし、これに任意の文字列を続けて名前を与えます。上図は次のように3つのトリプルで表現できます。
例2
<http://example.org/tokyo/survey/traffic/A00101> <http://example.org/tokyo/terms/平均値>_:average._:average<http://www.w3.org/1999/02/22-rdf-syntax-ns#value> "25.4" ._:average<http://example.org/tokyo/terms/unit> <http://example.org/tokyo/terms/kmph> .
なおここで与えた空白ノードIDはこの場限りの識別子で、N-Triplesのデータをアプリケーションが読み取った時には異なる(アプリケーション独自の)空白ノードIDが割り当てられることがあります。
人が読み書きしやすい記述:Turtle
N-TriplesがあればRDFグラフは完全に表現できますが、URIが羅列される形になるので、人間にとって読み書きしやすいものではありません。N-Triplesをベースにいくつかの簡略記法を加えて扱いやすくした構文がTurtleです。
Turtleの基本構文
簡略化の第1は、URIの短縮記法です。前の例を見ても分かるように、述語は語彙(プロパティやクラスをまとめて定義したもの)共通の比較的長いURIに単語(ローカル名)を付加した形になることが普通ですから、共通部分を略記できればコンパクトで見通しが良くなります。Turtleでは@prefixキーワードを使って、略記文字列(接頭辞)と元のURIを対応付け、データの記述には「接頭辞:ローカル名」の形を用います。また@baseキーワードで基底URIを指定すれば相対URIも使えます。
例3
@base<http://example.org/tokyo/survey/traffic/> .@prefixrdf:<http://www.w3.org/1999/02/22-rdf-syntax-ns#> .@prefixex:<http://example.org/tokyo/terms/> . <A00101>ex:平均値 _:average . _:averagerdf:value "25.4" . _:averageex:unitex:kmph .
ここで2番めと3番目のトリプルは同じ主語_:averageを共有しています。Turtleでは、主語が反復されるときは最初のトリプルの末尾をピリオド(.)の代わりにセミコロン(;)とすることで、次の主語を省略できます。
例4
@base <http://example.org/tokyo/survey/traffic/> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix ex: <http://example.org/tokyo/terms/> .
<A00101>
ex:平均値 _:average .
_:average
rdf:value "25.4" ;
ex:unit ex:kmph .
HTMLなどと同じようにTurtleやN-Triplesでは改行は空白文字の一種となるので、例4でも主語の後に改行を入れ、述語と目的語の対を並べてみました。主語反復の略記法と組み合わせると、同じ主語を持つ「レコード」の属性―値対として読むことができるため、データの構造を理解しやすくなります。
空白ノードと型
さらにTurtleでは、空白ノードを[]で表現し、その空白ノードを主語とするプロパティー目的語をその内部に列挙することができます。
例5
@base <http://example.org/tokyo/survey/traffic/> . @prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> . @prefix ex: <http://example.org/tokyo/terms/> . <A00101> ex:平均値[rdf:value "25.4" ; ex:unit ex:kmph].
空白ノードIDを考える必要がないことに加え、データの入れ子構造を直接示すことができるので、とてもよく用いられる記法です。
もうひとつ、型(クラス)を表す述語rdf:typeは頻繁に使われるので、Turtleではこれをaの1文字で省略表記できます。たとえば例5のA00101がex:Surveyというクラスのインスタンスだとすると次のような具合です。
例6
@base <http://example.org/tokyo/survey/traffic/> . @prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> . @prefix ex: <http://example.org/tokyo/terms/> . <A00101>aex:Survey; ex:平均値 [ rdf:value "25.4" ; ex:unit ex:kmph ] .
Turtleはこのように人間にとって理解しやすく、プログラムにとってもN-Triplesの拡張版として処理しやすいので、現時点でもっともよく利用される構文です。たとえばRDFを用いるW3Cの仕様書では例がTurtleで記述されるケースが大半ですし、標準化が進むLinked Data Platform仕様ではTurtleのサポートが必須となっています。
既存データとLinked Data:JSON-LD
ウェブアプリケーションを中心に頻繁に用いられるようになったデータ記述構文がJSONです。プロパティと値の対によるオブジェクトを基本に、値を列挙する配列を用いることができ、XMLと同様に入れ子によるツリー構造を表現します。
例7
{
"平均値" : {
"value" : "25.4" ,
"unit" : "kmph"
}
}
Turtleの[]を用いた記述法に近いと思いませんか? ただしこのままでは、RDFにとって非常に重要な主語を示す方法、またURIとリテラルを区別する方法がないので、RDFの記述に用いるには一工夫必要です。
JSON-LDの基本構文
RDFをJSONで記述する構文はいくつか考案されてきましたが、2014年1月にJSON-LD 1.0がW3C勧告となりました。LDはLinked Dataを意味し、まさにJSONでデータの主語、そしてURIを記述できるようにするものです。
まずN-Triplesと同様に、必要な箇所をURIにしてみましょう。
例8
{
"http://example.org/tokyo/terms/平均値" : {
"http://www.w3.org/1999/02/22-rdf-syntax-ns#value" : "25.4" ,
"http://example.org/tokyo/terms/unit" : "http://example.org/tokyo/terms/kmph"
}
}
JSONのプロパティはRDFの述語に相当しますから、ここにURIを書けばリテラルではないことは明らかです。問題はプロパティの値となる目的語です。"http://example.org/tokyo/terms/kmph"は見るからにURIのようですが、これは"http"で始まっているリテラル値かもしれないのです(実際この場合、JSON-LDではリテラル値として扱われます)。
JSON-LDは@で始まるいくつかのキーワードを導入しています。その一つである@idキーワードをプロパティとすると、値はURIとして解釈されます。あるオブジェクトに@idプロパティ値があれば、その値はオブジェクトのURIを表すのです。従って次のような記述で、全体の主語URIを示し、またunitの値をURIとする(URIで表されるオブジェクトとする)ことができます。
例9
{
"@id" : "http://example.org/tokyo/survey/traffic/A00101" ,
"http://example.org/tokyo/terms/平均値" : {
"http://www.w3.org/1999/02/22-rdf-syntax-ns#value" : "25.4" ,
"http://example.org/tokyo/terms/unit" : {"@id" : "http://example.org/tokyo/terms/kmph"}
}
}
これで例2以降で用いてきたRDFグラフが表現できました。
コンテクスト情報による省略構文
プロパティがURIとして記述できるのはよいのですが、やはり読み書きには不便なのでTurtleの@prefixのような短縮記法が欲しいところです。JSON-LDでは同様な記法を利用するために、@contextキーワードで短縮記述をURIに展開する情報を提供するようにしています。
@contextプロパティの値にはさまざまな情報を記述できますが、Turtleとの対比で分かりやすいのは、接頭辞とそのURIをプロパティ:値の対で記述するものです。また例えばex:unitの値は常にURIであると決まっているような場合は、@typeキーワードを用い"ex:unit" : {"@type" : "@id"}という情報を記述しておくことで、データのex:unitの値に直接URI文字列を記述することができます。
これを用いるとTurtleの例5にとてもよく似た形での表現が可能になります。
例10
{
"@context" : {
"ex" : "http://example.org/tokyo/terms/" ,
"rdf" : "http://www.w3.org/1999/02/22-rdf-syntax-ns#" ,
"ex:unit" : {"@type" : "@id"}
} ,
"@id" : "http://example.org/tokyo/survey/traffic/A00101" ,
"ex:平均値" : {
"rdf:value" : "25.4" ,
"ex:unit" : "ex:kmph"
}
}
データが複数あるときは、キーワード@graphをプロパティとしてデータを配列にまとめ、全体にコンテクストを適用できます。また、コンテクストは別ファイルにしてURIで参照することもできます。例10のコンテクスト部分をhttp://example.org/tokyo/context.jsonldに保存したとすれば、次のようになります。
例11
{
"@context" : "http://example.org/tokyo/context.jsonld" ,
"@graph" : [
{
"@id" : "http://example.org/tokyo/survey/traffic/A00101" ,
"ex:平均値" : {
"rdf:value" : "25.4" ,
"ex:unit" : "ex:kmph"
}
} ,
{
"@id" : "http://example.org/tokyo/survey/traffic/A00102" ,
"ex:平均値" : {
"rdf:value" : "32.1" ,
"ex:unit" : "ex:kmph"
}
}
]
}
JSONをJSON-LDとして利用する
一歩進めて、コンテクストで個々のプロパティにそれぞれURIを対応付けておけば、データのプロパティは接頭辞なしのローカル名だけにすることができます。また、マッピングの値をURIではなく"@id"とすれば、そのプロパティはオブジェクトの主語として扱われる(つまり"@id"に置き換えられる)ことになります。同様に@graphキーワードも通常のJSONプロパティにマッピングできます。さらに@baseキーワードを用いれば、Turtleと同じく基底URIを指定できるので、主語URIを単純なIDだけにすることも可能です。
これらを組合せてコンテクストファイルを次のようにすると
例12
{
"@context" : {
"@base" : "http://example.org/tokyo/survey/traffic/" ,
"ID" : "@id" ,
"data" : "@graph" ,
"平均値" : "http://example.org/tokyo/terms/平均値" ,
"value" : "http://www.w3.org/1999/02/22-rdf-syntax-ns#value" ,
"unit" : {
"@id" : "http://example.org/tokyo/terms/unit" ,
"@type" : "@id"
} ,
"kmph" : "http://example.org/tokyo/terms/kmph"
}
}
次のようなごくシンプルなJSONをJSON-LDとして(つまりRDFとして)解釈できるようになります。
例13
{
"@context" : "http://example.org/tokyo/jsonld-context" ,
"data" : [
{
"ID" : "A00101" ,
"平均値" : {
"value" : "25.4" ,
"unit" : "kmph"
}
} ,
{
"ID" : "A00102" ,
"平均値" : {
"value" : "32.1" ,
"unit" : "kmph"
}
}
]
}
コンテクストを工夫すれば一般的なJSONがRDFになるのですから、応用の範囲はとても広いといえるでしょう。
XMLデータのRDF化
同じく既存のデータ記述構文を利用してRDFを表現するものとして、XMLに基づくRDF/XML構文があります。最近はTurtleやJSON-LDが主流になりつつありますが、RDF/XMLもまだ広く用いられているので、簡単に紹介しておきましょう。
RDFの主語(S)、述語(P)、目的語(O)をXMLのツリー構造とするために、主語/目的語(ノード)を表すDescriptionという要素を導入し、その間に述語要素をサンドイッチとします。ノードのURIはaboutという属性で示します(about属性がない場合は空白ノードとなります)。
これらのRDF/XML記述用語彙は、Turtleでrdf:に割り当てたURIをXML名前空間として定義されます。RDFのトリプルを複数列挙する場合もXMLとしては一つのツリーにまとめる必要があるので、全体をRDF要素で囲み、通常そこでXML名前空間を宣言します。
N-Triplesの例2の最初のトリプルをRDF/XMLで記述してみましょう。空白ノードIDはaboutではなくnodeID属性で記述します。
例14
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:ex="http://example.org/tokyo/terms/" > <rdf:Descriptionrdf:about="http://example.org/tokyo/survey/traffic/A00101"> <ex:平均値> <rdf:Descriptionrdf:nodeID="average"/> </ex:平均値> </rdf:Description> </rdf:RDF>
主語が同じ場合はrdf:Description要素内にプロパティ要素を列挙できます。また目的語がリテラルの場合は、rdf:Description要素を用いず、値をプロパティ要素のテキスト内容として記述します。
RDF/XMLの省略構文
トリプルが連結できる、つまりあるトリプルの目的語と別のトリプルの主語のURIもしくは空白ノードIDが同じ場合は、XMLの入れ子として表現できます。また逆に、目的語のrdf:Description要素が子要素をもたない場合は、目的語のURIをプロパティ要素にrdf:resource属性で記述し、目的語要素を省略することができます。
型(クラス)を示すためにはrdf:type要素にrdf:resourceでクラスURIを記述することになりますが、やはりよく使われるのでRDF/XMLでも簡便な記法が用意されています。この場合は、主語ノードのrdf:Description要素をクラスの修飾名表記で置き換えてしまうのです。次はTurtleの例6と同じグラフを表現しています。
例15
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:ex="http://example.org/tokyo/terms/" > <ex:Surveyrdf:about="http://example.org/tokyo/survey/traffic/A00101"> <ex:平均値> <rdf:Description> <rdf:value>25.4</rdf:value> <ex:unitrdf:resource="http://example.org/tokyo/terms/kmph"/> </rdf:Description> </ex:平均値> </ex:Survey> </rdf:RDF>
ノード要素がクラス名になっているRDF/XMLは、rdf:Description要素を使うものよりむしろ頻繁に目にします。RDFを意識しない通常のXMLとして考えた場合にもこちらのほうが自然に見えるでしょう。ここではこれ以上取り上げませんが、このほかにも構文を柔軟にするための省略記法が複数用意されています。JSON-LDが一般的なJSONをRDFとして解釈できるようにしたのと同様に、RDF/XMLは普通のXMLのRDF化を可能にするのです。
Schema.orgとJSON-LD
前回は作品とイベントの情報をRDFとして記述し、そこで用いる語彙としてSchema.orgを紹介しました。この語彙は非常に幅広い分野をカバーするので、情報の種類にかかわらず同じ基本プロパティを用いた検索や処理が可能となり、「データのアクセシビリティ」が向上する可能性があるという趣旨でした。
Schema.orgはJSON-LDのコンテクストを提供し、自然な形でこの語彙を利用できるようにしています。
Schema.org語彙のグラフをJSON-LDで記述する
前回、例として取り上げたグラフの一部は次のようなものです。
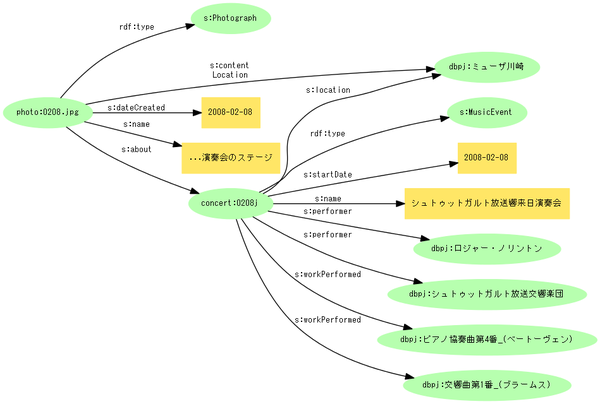
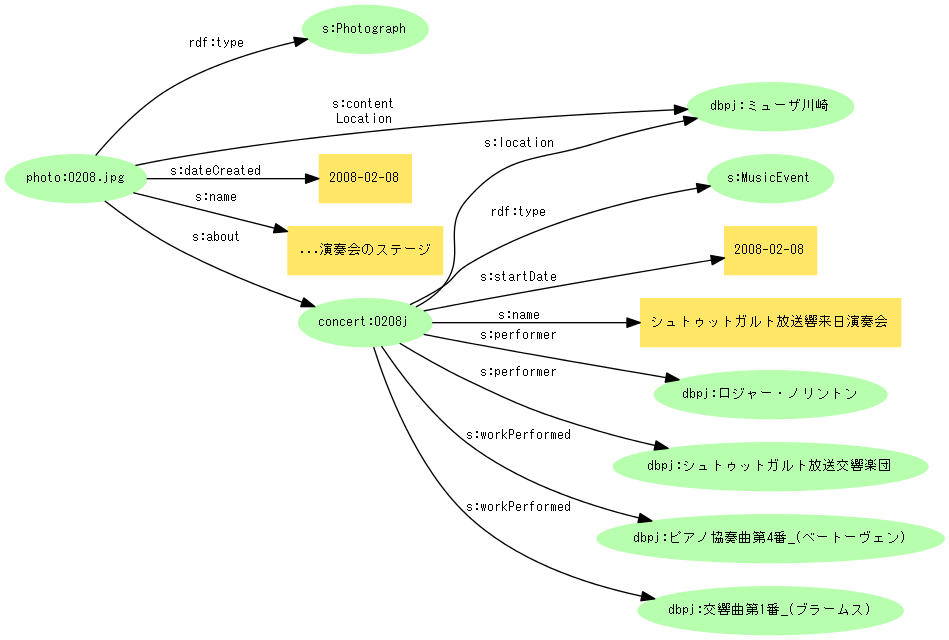
このグラフの、まず写真部分をJSON-LDで記述してみましょう。Schema.org自身が提供するコンテクストをURIで参照すれば、プロパティに接頭辞を加える必要がありません。
例16
{
"@context" : "http://schema.org/" ,
"@id" : "http://example.org/photo/2008/0208.jpg" ,
"@type" : "Photograph" ,
"contentLocation" : {"@id" : "http://ja.dbpedia.org/resource/ミューザ川崎"} ,
"dateCreated" : "2008-02-08" ,
"name" : "...演奏会のステージ" ,
"about" : {"@id" : "http://example.org/concert/2008j"}
}
初めて用いた記法として、@typeキーワードをプロパティにすることでクラス(型)を表しています。Turtleのaと同様、しばしば用いるプロパティを略記するとともに、rdfという接頭辞のマッピングが不要になっています。
次に演奏会データです。基本的には同じことですが、performerやworkPerformedのように値が複数ある場合、プロパティを繰り返すことはできないので、値を配列として記述します。
例17
{
"@context" : "http://schema.org/" ,
"@id" : "http://example.org/concert/2008j" ,
"@type" : "MusicEvent" ,
"startDate" : "2008-02-08" ,
"name" : "シュトゥットガルト放送響来日演奏会" ,
"location" : {"@id" : "http://ja.dbpedia.org/resource/ミューザ川崎"} ,
"performer" : [
{"@id" : "http://ja.dbpedia.org/resource/ロジャー・ノリントン"} ,
{"@id" : "http://ja.dbpedia.org/resource/シュトゥットガルト放送交響楽団"}
] ,
"workPerformed" : [
{"@id" : "http://ja.dbpedia.org/resource/ピアノ協奏曲第4番_(ベートーヴェン)"} ,
{"@id" : "http://ja.dbpedia.org/resource/交響曲第1番_(ブラームス)"}
]
}
Schema.orgが提供するコンテクストではperformerなどの値がURIに固定されていないので、これらの値を@idキーワードなしに記述するためには追加のコンテクストが必要になります。この場合は、@contextの値を配列として複数のコンテクストを列挙します。
では、コンテクストを追加して簡略表記すると同時に、例16と例17の2つのデータをまとめましょう。@graphキーワードを用いて両者を並べることもできますが、ここでは入れ子の形をとってみます。
例18
{
"@context" : [
"http://schema.org/" ,
{
"contentLocation" : {"@type" : "@id"} ,
"location" : {"@type" : "@id"} ,
"performer" : {"@type" : "@id"} ,
"workPerformed" : {"@type" : "@id"}
}
] ,
"@id" : "http://example.org/photo/2008/0208.jpg" ,
"@type" : "Photograph" ,
"contentLocation" : "http://ja.dbpedia.org/resource/ミューザ川崎" ,
"dateCreated" : "2008-02-08" ,
"name" : "...演奏会のステージ" ,
"about" : {
"@id" : "http://example.org/concert/2008j" ,
"@type" : "MusicEvent" ,
"startDate" : "2008-02-08" ,
"name" : "シュトゥットガルト放送響来日演奏会" ,
"location" : "http://ja.dbpedia.org/resource/ミューザ川崎" ,
"performer" : [
"http://ja.dbpedia.org/resource/ロジャー・ノリントン" ,
"http://ja.dbpedia.org/resource/シュトゥットガルト放送交響楽団"
] ,
"workPerformed" : [
"http://ja.dbpedia.org/resource/ピアノ協奏曲第4番_(ベートーヴェン)" ,
"http://ja.dbpedia.org/resource/交響曲第1番_(ブラームス)"
]
}
}
追加コンテクストで"dbpj" : "http://ja.dbpedia.org/resource/"などとしてURIを短縮表記することもできますが、純粋なJSONとしても利用することを考えるなら、値はURIのままにしておくほうが扱いやすいかもしれません。
Schema.org+JSON-LDのメリット
JSON-LDはRDFアプリケーションにとってはRDFグラフの表現ですが、プログラミング言語一般から見ればJSONオブジェクトとして扱うことができます。例えば例18を解析してphotoというオブジェクト変数に読み込んだ場合、プログラムは撮影対象の演奏会場をphoto.about.locationといった形で取得でき、独自の応用処理が可能です。
先般GoogleがHTMLページ内にJSON-LDで記述されたSchema.org語彙に対応すると表明したのも、この組み合わせのメリットと言えるでしょう。HTMLページ内にJSON-LDを記述するにはscript要素を使います。
例19
<script type="application/ld+json">
{
"@context" : "http://schema.org/" ,
"@id" : "http://example.org/concert/2008j" ,
...
}
</script>
HTMLページへのSchema.org語彙埋め込みにはmicrodataを使う方法もあります。microdataからRDFを抽出することもできるので、どちらでも構わないのですが、カタログやイベント情報などデータベースに基づくようなページの場合、JSON-LDの方が扱いやすいかもしれません。HTMLは直接記述せず、JSON-LDからJavaScriptフレームワークを使うなどして動的にHTMLを生成すれば、システマティックなページづくりができると同時に検索エンジンにもインデックスされやすいという利点も得られるでしょう。
RDFの利用と構文
ここまで見てきたように、RDFグラフを具体的に記述する構文は用途に応じて複数用意されています。RDFを利用するためには、これらの構文をみな理解しておく必要があるのでしょうか。
利用者にとっての構文
RDFデータを利用する場合は、アプリケーションが処理してくれればよいのですから、構文の知識はなくても大丈夫とも言えます。ただ、新しいデータセットを利用するときに、そこにどんな情報がどのようなモデルで表現されているのかを理解するためには、サンプルデータや説明文書を読む必要があり、構文が分からないと先に進めません。サンプルデータ程度のRDFならば、RDF TranslatorやRDF Distillerなど構文変換をしてくれるツールがあるので、どれかひとつの構文からRDFグラフを読み取ることができれば十分です(グラフ視覚化ツールを利用するのもよい手です)。
また、RDFデータセットから必要な情報を取り出すためにはSPARQLという言語で検索クエリを記述しなければなりません。SPARQLはTurtleの上位互換構文を用いるので、この点でもTurtleを理解しておくのは得策でしょう(SPARQLについては回を改めて紹介します)。
提供者にとっての構文
RDFデータを提供する立場の場合は、データベースにRDFグラフを格納するためにまず何らかの構文でデータを記述しなければなりません。そのデータを正しいモデルとして表現できるように、少なくともひとつの構文はきちんと理解しておく必要があります。
前述のとおり今後のLinked Data PlatformではTurtleが必須構文となる方向ですから、RDFを提供するサービスはTurtleのサポートが求められるようになるでしょう。またウェブアプリケーションでの利用を考えればJSON-LDを提供できると好都合ですし、RDF/XMLを前提としたシステムもまだ少なくないはずですから合わせて提供したいところです。
RDFを格納するデータベースやライブラリは、通常RDFグラフをさまざまな構文で表現する機能を備えており、グラフを異なる構文で書き出すことは難しくありません。多様な用途に対応できるよう、利用者のリクエストに応じて複数の構文で提供できる設計としておくことが望まれます。
Linked Open Data・RDFの活用ソリューションならインフォコム


