










OpenText製品概要
OpenTextは世界最高水準の超高速全文検索エンジンです。
XML/Unicode対応なので、複雑な文書構造のXML文書に対する全文検索や、複数の言語が混在したテキストデータの検索をシンプルかつパワフルに実行します。
XMLをデータ交換フォーマットのみでなく、そのままデータベースとして活用することが可能です。
複数の検索サーバを利用して1つの巨大なデータベースを構築する場合においてもフレキシブルな対応が可能となります。
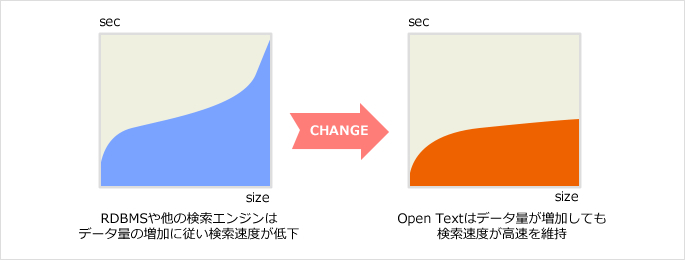
世界超高速レベルの検索速度
全文検索システムに求められる絶対的な機能とは、「高速」な検索性能です。
多くの検索エンジンは検索処理能力の限界からストップワードを必要とし、「the」「is」「a」などの単語を検索できない場合がありますが、OpenTextの検索性能はストップワードを必要としないほど超高速です。
構造化文書対応
OpenTextはXMLとSGMLにネイティブに対応しているため、複雑な構造を持つ文書データに対しての検索も超高速です。
特定の項目だけを対象に検索することも、複数の項目や属性を掛け合わせて検索することも自由自在です。もちろん全文検索も可能であるため、RDBMSとは異なるスムーズなXML文書の利用環境を提供します。
Unicode対応
OpenTextはUnicode(UTF-8)に対応しているため、全世界の文字を利用することができるだけでなく、複数言語が混在しているデータでも問題ありません。
OpenTextに投入すればどんな言語でも検索することが可能となります。
シンプルな構成
OpenTextは強力で複雑な検索クエリーを処理することができますが、開発者や利用者へのインターフェースは非常にシンプルです。
例えば、簡単なデータベースを作成するだけであれば検索対象のファイルを用意して、わずか2つの検索コマンドだけで全文検索データベースを作成することができます。
WebInterfaceを利用すれば、ボタン一つで全文検索データベースの構築が可能です。
検索においてはシンプルな検索コマンドを組み合わせる事で、驚くほど柔軟で多様な検索を実現します。
統合検索
OpenTextを利用すれば複数のデータベースを統合検索することも簡単です。
統合するデータベースは複数のサーバに分散していても、同一サーバに存在していても構いません。
統合検索を行う場合でも、ユーザの作業は単一データベースを扱う場合と変わりません。
OpenTextなら巨大なデータベースの構築も検索も簡単なのです。
OpenText 主な機能
| 検索機能 | 単純検索 論理演算検索 AND検索、OR検索、NOT検索 括弧による演算 近傍検索 NEAR、FBY 範囲検索 文書構造検索機能 ※1 エレメント検索(タグ)、アトリビュート検索(属性) ネームスペース対応検索 文字マッピング機能 シソーラス機能 ※2 ランキング機能 ソート機能(ランキングソート可能) 検索履歴保存 検索結果保存 検索コマンドバッチ実行機能 |
|---|---|
| 対応文字コード | UTF-8 / EUC / SJIS / その他 |
| Web Interface機能 | データベース管理機能 インデックス作成機能 キーワード検索機能 範囲検索機能 複合検索機能 検索結果一覧表示機能 詳細表示機能 文書表示機能、ハイライト表示機能 |
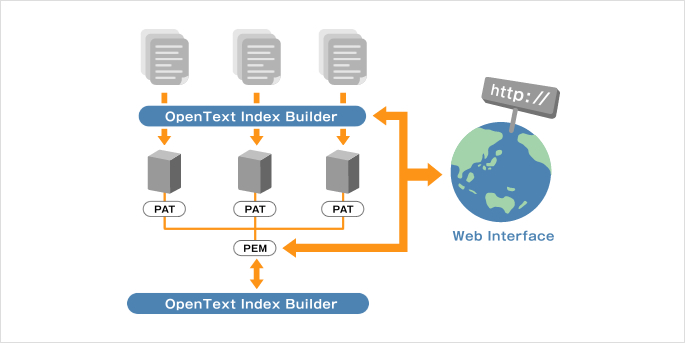
| 格納モジュール | 全文検索実行モジュール 並列検索実行モジュール インデックスポイント抽出モジュール 全文検索インデックス作成モジュール 構造検索インデックス作成モジュール Web Interfaceモジュール |
※1 XML/SGML/HTML
※2 別途シソーラス辞書が必要になります。
OpenText 機能概要





まずはお気軽にご相談ください。デモも行っております。