Digital Archive System - Library, Public records, Museum - Infocom


Official archives, ancient documents, valuable papers, research results, academic publications. InfoLib is digital archive system, designed to give the public easy access to all information available on the internet. It functions as an institutional repository system which releases digital informationarchive systems, such as official archives, ancient documents, valuable papers, research results, academic publications, research results and academic knowledge. It also contains a growing thesis database. By adapting to international standards, the InfoLib digital archive system has the ability to collaborate or connect with other external institutions.
The InfoLib Digital Archive System uses a simple and easy-to-use screen interfaces, allowing in order for users to find data easily.
Constructing a Web database takes only four steps from registration to the publishing of data. Technical skills are not required for any of these steps.
All operations can be performed through a Web Browser. There is no need for special plug-ins.
InfoLib is Unicode ( UTF-8 ) enabled. This allows you to deal with data in multiple languages.
InfoLib supports Dublin Core metadata. Dublin Core is the most developed metadata element set. It is also designed to work with other metadata elements.
High speed search can be performed using a specified XML tag structure.
By using OpenText? as search engine, the system is capable of super high speed searches.
Registered data can be released in accordance with the International Standard Z39.50. By using the WWW and Z39.50 as a gateway, searches across different Z39.50 servers can be performed. InfoLib can also search across other InfoLib systems.
InfoLib is OAI-PMH ( Open Archives Initiative Protocol for Metadata Harvesting ) enabled. OAI-PMH is a communication protocol for metadata exchange. This means that registered data can be released at an OAI-PMH repository. It is also possible to gather metadata from other repositories through the OAI-PMH harvester.
InfoLib is SRW ( Search / Retrieve Web Service ) enabled, according to the Z39.50 standard, which has been attracting attention as a next-generation technology. This means that the registered data can be published through SRW.

Nowadays, with so much information available, new technology is needed that allows you to quickly find the exact information you need, regardless of format. To meet this need, InfoLib has been developed to effectively use all kinds of digital information. InfoLib uses the highly advanced search platform OpenText? ( Canadian Open Text Corporation ) to target information quickly and efficiently, though the use of the XML supported high-speed search engine OpenText? at the system core.
InfoLib-META is a high speed, full text retrieval system. Any metadata created through InfoLib-EDIT can be quickly searched and viewed on a web browser. Thanks to the OpenText? engine, XML data can be searched quickly and directly using full text search functionality.
The XML search function enables searchers to find specific data by defining a XML data structure ( tags and classifications ). The search function is able to respond, without stress, to complex search criteria with a variety of items and keywords.
The data created through the InfoLib-EDIT system can be accessed and searched through the InfoLib-META system. This search can be specified through a hierarchical structure, or narrowed down to a search of limited target data classifications.
InfoLib-EDIT is a metadata editing and control system, based on XML. It also controls metadata editing, which is necessary for digital archiving. Metadata can be added, edited, and deleted through a web browser. This can be done without needing to worry about XML structure. For advanced users, text editing is also possible via XLM forms.
It is possible to output and register metadata in both CSV format and XML format at the same time.
Metadata schema ( data structure ) can be applied according to personal preference. The system uses the Dublin Core Simple Element Set as default.
Archived metadata can be stored and managed in categories. The system allows for a hierarchical structure; making a large amount of archived data easy to search, sort through, and classify.
This feature manages contents files. The content data can be managed in a web browser ( registration, editing, and deletion of data ).
By using the XML formatted export and import feature, the system supports the transfer and registration of large amounts of archived metadata.
Users are registered simply by filling out certain information in the web browser. Users can be managed in groups and administrative control can be assigned to each individual group, making management an easy task. User information can also be updated by the users themselves.
![[ InfoLib-Basic Package ] System Image](e-img/il1.jpg)

InfoLib-DBR is designed as a package to create and distinguish specified databases from different kinds of data, and to release the data integrally. The advantage of InfoLib-DBR is easy database building by simply adding brief set-ups on CSV data. The individual databases can be related to others, regardless of type, and so can be used in a wide range of settings.
Simple Database Compilation by adding brief establishment to register. Based on the registered data, InfoLib-DBR automatically creates a search page, a search list page and detail-indicated pages. These pages are available in two languages; Japanese and English.
Expert knowledge is not required to register the data; anyone can easily follow the wizard through the four simple steps involved.
Different database types can be created.
The high-speed search engine OpenText? supports XML, allowing for stress-free search.
Data in CSV and XML can be registered immediately.
You can edit and remove the registered data. Adding new data is also supported.
You can personalize page design according to your tastes. The top banner, background color, search page background image, and page description can be altered for each database.
A categorized search page is automatically created by extracting tagged category information from the registered data.
Automatic browse search page are created to enable you to view the defined data items. You can run the search by selecting it from the index.
In case the registered data has an image URL, you can refer to the corresponding image page. A page turning effect and thumbnail image presentation is also available.
The list of search results is shown using a hierarchical grouping.
Pull-down lists, list boxes, check boxes etc. can be arranged on the search page.
You can search across all registered databases.
The monthly usage statistics are shown for each database.
Z39.50 target on registered data can be released through a simple set-up procedure. No specific knowledge or skills are required to follow this procedure.
OAI-PMH repository on registered data can be released through a simple set-up procedure. The OAI-PMH repository supports the jun2ii format, as an institutional repository and the data can be made available to the National Institute of Informatics.
![[ InfoLib-DBR ] System Image](e-img/il2.jpg)
Search

Search result list
Details

Thumbnail image
Image zoom

Administrator

InfoLib-GlobalFinder is a package which is compliant with Z39.50 ( ISO 23950, an international information search protocol standard ) and SRW. Through InfoLib-GlobalFinder, it is possible to perform searches across Z39.50/SRW servers on the internet, and database releases are enabled. This means that service linking with external institutes is provided.
InfoLib-GlobalFinder can manage searches across Z39.50 or any internet-enabled SRW database. Without having to worry about the differences between search protocols, users can access different databases in the same manner.
InfoLib-GlobalFinder uses a multi-targeting feature which can specify multiple servers at once and perform cross-searches within.
InfoLib-GlobalFinder uses Z39.50 and SRW servers for data sharing. Once created, the database is released to the public through Z39.50 or SRW. Data from the database can be released in XML forms and SGML forms, regardless of whether it is registered at InfoLib or not.
![[ InfoLib-Global Finder ] System Image](e-img/il3.jpg)
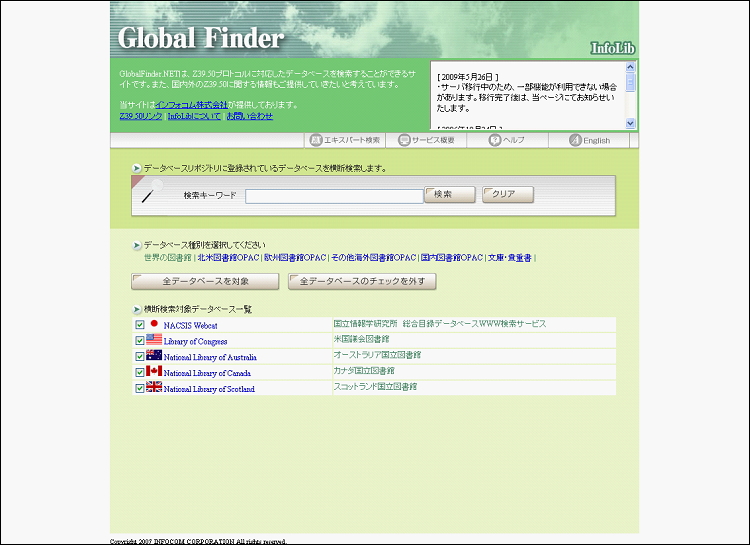
Top page

InfoLib-PMH is an institutional repository package which supports OAI-PHM ver. 2.0. InfoLib-PMH supports both the harvesting function which collects metadata from OAI-PMH supported repositories, and the repository function which releases the collected metadata to the public.
InfoLib-PMH can harvest metadata from an OAI-PMH supported repository ( data provider ), and the metadata can be automatically stored and managed in the InfoLib database. InfoLib-PMH harvester can also register various repositories as harvesting targets.
Support for the OAI-PHM repository feature is provided. The collected metadata from external repositories can be easily released as OAI-PHM repository data. When a database is released, you can set-up various formats for providing metadata ( Dublin Core and junii2 are provided as standard ).
The harvested metadata can be divided and managed through records. The metadata can be edited and deleted using a web browser.
InfoLib-PMH contains a metadata conversion feature which transforms the harvested metadata into a database to be searched with InfoLib-META. Multiple configurations for the data conversion can be registered. Data conversion criteria and scheduling can be set according to preference.
![[ InfoLib-PMH ] System Image](e-img/il4.jpg)

InfoLib-LOD is a software package
for the easy publication
of data.
We have started selling InfoLib-LOD
Up to now, Infocom has provided the metadata design and digital archive construction for a large number of archives, libraries, and museums. Now, taking advantage of this know-how, we have developed and started to offer the "InfoLib-LOD" software package. Using this package, anyone can easily expose their data in the Linked Open Data format (LOD)
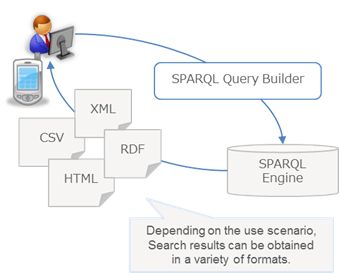
With "InfoLib-LOD", any data held in CSV, XML, RDF, RDBMS and other formats can be converted and published in the LOD description format. Data search is made possible by using the query language SPARQL for RDF. By using a standard, application independent language (RDF) in our API, SPARQL queries can be performed to collect and increase the utilization of data. Also, if you are already using "InfoLib", you can publish the data as LOD by using it in conjunction with "InfoLib-LOD".
When using "InfoLib-LOD" to transform your data into LOD, increased data re-use is possible. For example, with the promotion of open government in the public sector and research institutes can use this data for data analysis.
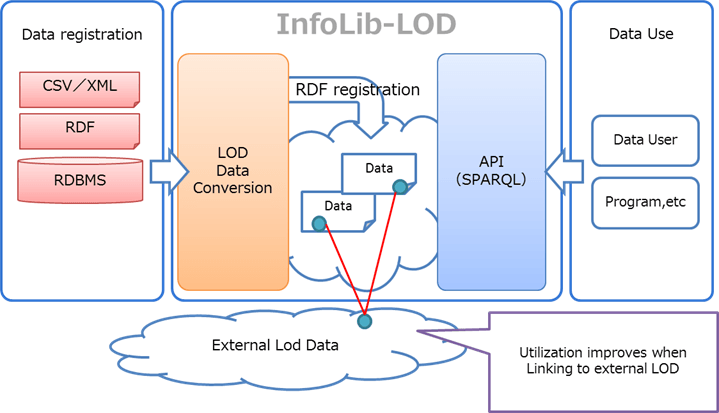
The newly released "InfoLib-LOD" is an important part of our lineup and enables us to meet the needs of our customers. Existing customers using the InfoLib series can work with InfoLib-LOD without modification on currently registered data. In addition, for customers that are not already using InfoLib for their current data, we provide a combination of packages to meet any customer needs.
Over the next five years, we plan to implement our solutions in more than 120 institutions, ranging from archives, libraries, and research institutions to the center of national government.
Background for the Development of InfoLib-LOD
In July 2012, the government formulated the "electronic government open data strategy" in order to promote the opening up of public data. In the United States and EU countries, the opening of data has been going on for some time, as part of the push towards open government. It is expected that more and more data engines and public data will be created open as new services are introduced.
A number of different formats have been adopted for the sharing of open data. In particular, LOD has been attracting attention as an effective means to share data and knowledge. This is especially the case when publishing data on the web.
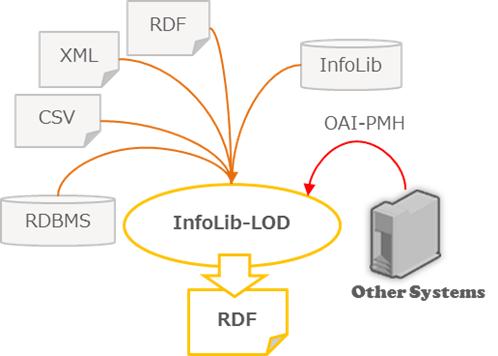
 | Conversion of different data to RDF |
With InfoLib-LOD, it is not only possible to register RDF. InfoLib-LOD also comes equipped with functionality to convert RDF, RDBMS or CSV to RDF.
- A variety of text files can be converted to RDF
- The system converts to RDF from CSV (TSV) or XML. It is also possible to register a file already in RDF.
- RDF conversion from RDBMS
- The system converts data stored in an RDBMS to RDF
- Cooperation with other InfoLib packages
- If you are using InfoLib already, no data creation is required. Data can be converted to RDF as it is.
- Cooperation using OAI-PMH
- It is also possible to collect data using the OAI-PMH protocol and convert it to RDF.
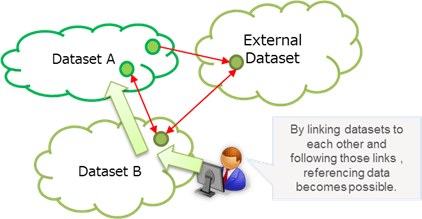
| Towards linked data |
Only when data has been linked to external data can it truly be called Linked Open Data. Registered data can be linked either to other registered data or to external data.
- Linking between data sets that have already been registered
- Data sharing and search is facilitated by linking between registered data.
- Linking to external data sets
- By using RDF for externally linked data, InfoLib conforms to the "5 stars" of Linked Open Data, as advocated by the W3C.
| Flexible search |
You can search registered data using SPARQL. In addition, search results can be retrieved in a variety of formats.
- Construction of a SPARQL endpoint
- Registered data can not only be searched by keyword, flexible search using SPARQL is also possible. In addition, there are enhanced support options available using the SPARQL Query Builder feature.
- Search results can be obtained in a variety of formats.
- SPARQL query results can be returned not only in HTML, but also in XML, JSON, N-triples, RDF / XML, CSV, TSV, etc.